UTF-8 定数
UTF-8 定数は、字類が UTF-8 の文字列である。このような定数は、基本表記または 16 進表記を使用して指定できる。
書き方 1 の一般形式
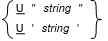
書き方 2 の一般形式
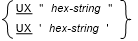
すべての書き方に関する一般規則
- 字類 UTF-8 の定数はネイティブ COBOL でのみサポートされる。
書き方 1 の一般規則
- 書き方 1 は基本表記と見なされる。
- string に DBCS 文字が含まれる場合は、シフトアウトおよびシフトイン制御文字で区切る必要がある。
- Unicode の可変幅の性質により、string 内で使用可能な最大文字数は変化する。
- string では、次の Unicode エスケープ シーケンスが許可される。
- \uhhhh
- 各 h は、0 から 9、a から f、および A から F の範囲の 16 進数値を表す。このエスケープ シーケンスは、U+0000 から U+FFFF の範囲内の、基本多言語面 (BMP) の Unicode コード ポイントに対応する。
- \U00hhhhhh
- 各 h は、0 から 9、a から f、および A から F の範囲の 16 進数値を表す。このエスケープ シーケンスは、基本多言語面または任意の追加面の Unicode コード ポイントに対応できる。つまり、上記の範囲だけでなく、U+10000 から U+10FFFF も含まれる。
注: コード ポイント U+D800 から U+DFFF は、UTF-16 で使用されるサロゲート ペアの上半分と下半分のために予約されている。したがって、\uD800 から \uDFFF および \U0000D800 から \U0000DFFF を UTF-8 定数の Unicode エスケープ シーケンスとして指定してはならない。\uhhhh または \U00hhhhhh を UTF-8 定数の文字列として含める場合は、エスケープ文字 (\) 自体をエスケープして (\ を使用)、文字列を文字どおりに解釈できる。たとえば、\\u00FF は Unicode エスケープ シーケンスとして処理されない。
書き方 2 の一般規則
- 書き方 2 は 16 進表記である。
- hex-string は、0 から 9、a から f、および A から F の範囲の 16 進数値で構成される。2 桁の各グループは、1 つの UTF-8 文字の単一の符号化を表す。
- hex-string で表されるバイト シーケンスは、有効な UTF-8 バイト シーケンスが含まれていることを確認するために検証される。有効なバイト シーケンスが含まれている場合、この 16 進表記は UTF-8 文字として格納され、同じ文字を指定する基本的な UTF-8 定数と同じ意味を持つ内容になる。
- 16 進表記の UTF-8 定数は、字類および項類が UTF-8 のデータを持ち、基本的な UTF-8 定数と区別なく使用できる。