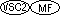
世界の言語の中には、日本語のように文字の数が数千にも及ぶ文字集合を使用しているものが数多くある。一方、たいていの計算機では、文字を表わすのに8ビットを使用し、8ビット・コードのそれぞれの値に別々の文字を割り当てている。この方式だと、256種類の文字までしか表わすことができない。
理想的には、COBOLのプログラマは文字を表わすための内部コードを意識する必要がないことが望ましい。しかし、実際には内部コードの特性がプログラマに影響を与えることがある。中でも、表わせる文字の数が256しかないということは、特に大きな制約である。
この問題に対処するため、2バイト文字集合(double-byte character set:DBCS)が用意されている。この方式では、各文字は隣接する2バイトからなる16ビットのコードで表わされる。この結果、数千種類の文字を表わすことが可能となる。
2バイト・コードを具体的にどのように文字に割り当てるかは、国によって異なっている。
COBOLシステムで使用されている8ビット・コードは、情報交換用米国標準コード(ASCII)である。この章では、ASCIIコードのことを、1バイト文字集合(single-byte character set)と呼ぶことにする。
 2バイト文字集合はDBCS指令の影響を受ける。
2バイト文字集合はDBCS指令の影響を受ける。
日本語支援の詳細については、2バイト文字支援機能のMicro Focus 拡張の章を参照。
DBCS指令を使用すると、COBOLシステムは2種類のコード体系を認識するようになる。これによって、データを2バイト文字形式で格納できるようになる。しかし、DBCS指令は他のコード体系を使用できないようにするわけではない。したがって、DBCS指令を使用しても、1バイト文字形式でデータを格納することができる。
必要なハードウェアを備えていれば、2バイト文字の形式で入力や出力に使用されるデータ項目が認識されて、画面やキーボードやプリンタなどの装置にそれらのデータを適正に表示したり、データを受け取ったりすることができる。
1バイト文字集合には、ローマ字のアルファベットとその他のいくつかの文字が含まれる。国によっては、2バイト文字集合の中に1バイト文字集合の中の文字の多くが含まれる。
ハードウェアによっては、データの格納方式が1バイトか2バイトかで、表示される文字の形態がはっきり異なるものがある。たとえば、画面によっては、2バイト・コードの文字の方が、1バイト・コードの文字よりも大きく表示される。
NTTのマルチベンダー統合体系(MIA)に合わせて作成したプログラムは、COBOLコンパイラによってコピーできる。このためには、DBCS指令およびCURRENCY-SIGN"92"指令を使用する。
2バイト・コード文字は、定数(定数はデータであるため)、注記、注記項、利用者語に使用できる。これ以外については、DBCS指令は原始プログラム中で使用できる文字の範囲を変更しない。つまり、プログラムは依然としてCOBOLの文字集合(言語リファレンスのCOBOL言語の概念の章を参照。) を使用して書かれている。
2バイト文字のデータを含むデータ項目を定義するために、PICTURE句とUSAGE句が拡張されている。2バイト文字のデータ用には、新しい形式の定数が必要である。
2バイト文字のデータの取扱いを定義するために、各種の指定や句や文に規則が追加されている。
特に断わりがないかぎり、COBOLのすべての機能と規則は、2バイト文字を使用する際にも適用される。 以下に記述するのは、2バイト文字に関して追加されている規則と書き方だけである。
注記および注記項の中では、1バイト文字と2バイト文字を自由に混ぜて書いてよい。
利用者語の中では、1バイト文字か2バイト文字のどちらかを使用できる。利用者語を使用するものには、符号系名、字類名、条件名、データ名/一意名、レコード名、ファイル名、指標名、呼び名、段落名、節名、記号文字がある。
利用者語の中では、1バイト文字と2バイト文字を自由に混ぜて書いてよい。ある文字が1バイト文字集合と2バイト文字集合の両方の中に存在するときは、それぞれに属する文字は異なるものとみなされる。(前述の2バイト文字集合とローマ字の節を参照。)
字類が2バイト文字のデータ中の空白は、2バイト・コードで表わされる。2バイト・コードで表わされた空白文字を、「全角の空白」と呼ぶ。
全角の空白に割り当てられる値は、DBCS指令およびDBSPACE指令の影響を受ける。
言語リファレンスのCOBOL言語の概念の章で説明した字類の他に「2バイト文字」を追加する。字類の2バイト文字には、項類として、2バイト文字と2バイト文字編集の2つが含まれる。
字類が2バイト文字のデータ項目を表わすには、USAGE DISPLAY-1句を使用する。この句を指定したデータ項目のPICTURE文字列には、文字"G"と"B" だけを書くことができる。" G" は2バイト文字の文字位置を表わす。"B" は編集文字であり、全角の空白を挿入する文字位置を表わす。PICTURE文字列がすべて"G" であるデータ項目の項類は、2バイト文字である。PICTURE文字列中に"G"と"B" が混在するデータ項目の項類は、2バイト文字編集である。
PICTURE文字の"G" と "B" は、どちらも1つの2バイト文字の文字位置を表わす。2バイト文字のデータ項目の長さは、そのPICTURE文字列中の"G" と "B" の数で表わす。ただし、例外として別途規定している場合もある。
部分参照では、最左端文字位置と長さはバイト数ではなく、2バイト文字の数で指定する。
字類が英数字のデータ項目を使用できる箇所であれば、どこでも字類が2バイト文字のデータ項目を使用してよい。ただし、この章で後述する該当する規則に従うものとする。また、これには例外もある。
項類が英数字のデータ項目中に収めたデータの中に、2バイト文字を含めることができる。このようなデータにおいては、1バイト文字は1バイト・コードで表わされ、2バイト文字は2バイト・コードで表わされる。空白は半角で表わされる。
入力および出力のとき、1バイト文字も2バイト文字も認識される。2バイト文字の最初のバイトは1バイト文字では使われないコードであるので、両者を一緒に使用しても混同されることはない。しかし、プログラム内でデータを操作する際には、2バイト文字も通常の英数字と同様に扱われる。したがって、2バイト文字の2つのバイトが分割されないようにすることは、プログラマの責任である。
この型のデータ項目の長さは、すべての場合において、バイト単位で数える。
言語リファレンスのCOBOL言語の概念の章で説明した文字定数と数字定数の他に、3番目の定数として2バイト文字定数が加えられている。
2バイト文字定数は、両端を引用符またはアポストロフィで囲み、その前に"G" を付けた文字列である。2バイト文字定数には、計算機の2バイト文字集合中の任意の文字を含めることができる。2バイト文字定数の長さは、2バイト文字で最長28文字までである。2バイト文字定数を行をまたがって継続することはできない。
引用符またはアポストロフィを区切り文字として使用した場合、2バイト文字定数の中にその区切り文字を含めるには、その文字を2つ続けて書く。区切り文字として使用していない引用符またはアポストロフィを2バイト文字定数の中に含める場合は、その文字を1つだけ書く。実行用プログラム内での2バイト文字定数の値は、文字列に下記の解釈を加えたものである。
文字定数を使用できる箇所であれば、どこでもすべての2バイト文字定数を使用することができる。ただし、この章で後述する該当する規則に従うものとする。また、これには例外もある。
文字定数の中に2バイト文字を含めることができる。2バイト文字が含まれる文字定数を「混合定数」と呼ぶ。このような定数においては、1バイト文字は1バイト・コードで表わされ、2バイト文字は2バイト・コードで表わされる。空白は半角で表わされる。
出力のとき、1バイト文字も2バイト文字も認識される。2バイト文字の最初のバイトは1バイト文字では使われないコードであるので、両者を一緒に使用しても混同されることはない。しかし、プログラム内でデータを操作する際には、2バイト文字定数も通常の文字定数と同様に扱われる。したがって、2バイト文字の2つのバイトが分割されないようにすることは、プログラマの責任である。
文字定数の項類は英数字であり、2バイト文字ではない。このことは、2バイト文字が含まれるか否かに左右されない。
混合定数を、行をまたがって継続することはできない。
この制限は解除されている。
(この章で記述する字類および項類に関する該当する規則に従って、)2バイト文字定数だけを使用できる箇所で表意定数を使用した場合、これは2バイト文字定数となる。この定数内の各空白は、全角である。
2バイト文字定数として使用できる表意定数は、SPACE(S)だけである。
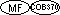
COBOL/370 および MIA COBOL仕様においては、2バイト文字定数に相当する、別の形式の定数が使用されている。

N"ABC""DEF"
この制限は解除された。
この制限は解除された。
または "N" であってもならない。
この制限は解除された。
PICTURE句で表せる項類が、2バイト文字と2バイト文字編集の2種類追加されている。この2つの項類は、共にUSAGE IS DISPLAY-1と記述しなければならない。
この2つの項類は、必ずしもUSAGE IS DISPLAY-1と記述しなくてもよい。
 DISPLAY-1 は PIC N項目には任意であるが、PIC G 項目では必ず必要である。
DISPLAY-1 は PIC N項目には任意であるが、PIC G 項目では必ず必要である。
と "N" だけである。
PICTURE文字列には、記号"G"と"B" を任意に組み合わせて含めることができる。
使用する記号の働きは下記のとおり。
| G - | 各"G"が、2バイト文字または全角の空白だけを含むことができる文字位置を表わす。 |
| B - | 各"B"が、全角の空白を挿入する文字位置を表わす。 |
|
|
各"N"が、2バイト文字または全角の空白だけを含むことができる文字位置を表わす。 |
1つの"G" または "B"
 または "N"
または "N"
は、2バイト文字の1つの文字位置を表わすことに注意。
データ項目にどのような編集をすることができるかは、そのデータ項目がどの項類に属するかによって決まる。「表 4-1 データの項類に適用できる編集の種類」(言語リファレンスのプログラムの定義の章を参照) に、下記の拡張を加える。
表 5-1 : 2バイト文字の項類に適用できる編集
| 項 類 |
編集の種類 |
|---|---|
| 2バイト文字 | なし |
| 2バイト文字編集 | 単に"B" を挿入するだけ |
1バイト文字データ項目中で使用した場合、"B"(空白)は半角の空白を表わす。 2バイト文字データ項目中で使用した場合は全角の空白を表わす。
この制限は解除された。
下記の書き方が追加されている。

したがって、USAGE IS DISPLAY-1句は、項目の字類を2バイト文字とする働きがあることに注意。
PICTURE文字列に
"G" または
"N" を指定した項目に、USAGE IS DISPLAY-1句を記述する必要はない。
PICTURE文字列に"G" が含まれていると、対応する項目の字類は2バイト文字とみなされる。
字類が2バイト文字に属するデータ項目および定数を 比較条件中に使用し、任意の比較演算子を適用できる。各作用対象は、集団項目または2バイト文字とする。データの変換、編集、逆編集は行われない。2バイト文字の項目と2バイト文字編集の項目とは、区別されない。
行われる比較は、文字の比較である。2バイト文字集合中の文字の間には、一般に文字の大小順序は付けられない。したがって、2バイト文字を2進数のようにみなして、その文字を表わすビット・パターンの数値に基づいて文字の大小順序を決定する。
2バイト文字の中に1バイト文字に相当する文字が含まれている場合、2バイト文字の大小順序に従って文字を並べたときに、1バイト文字に相当する文字が1バイト文字の文字の大小順序どおりに並べられる保証はないので注意すること。
ある文字が2バイト文字集合にも1バイト文字集合にも含まれている場合、その2バイト文字と1バイト文字は等しいとはみなされない。(前述の2バイト文字集合中のローマ字の節を参照。)
PROGRAM COLLATING SEQUENCE句は、字類が2バイト文字または2バイト文字定数のデータ項目の比較に関しては効力がない。
作用対象の長さが等しくない場合、長い方と同じになるまで短い方の後ろに全角の空白を付け加えたものとして、比較が行われる。
2バイト文字データ項目に対する字類検査は、2バイト文字および漢字である。
2バイト文字および漢字の字類検査はサポートされていない。
字類が2バイト文字のデータ項目同士の間、またはデータ項目と定数の間でデータを転記することに係わるすべての文は、この章で後述するMOVE文の2バイト文字の転記に関する一般規則に従う。
この制限は解除された。
この制限は解除された。
この制限は解除された。
この制限は解除された。
一般形式が拡張されて、ALPHABETICやALPHANUMERICなどのオプションの他に、DBCS,
NATIONAL, NATIONAL-EDITED
が加えられている。
NATIONAL, NATIONAL-EDITEDのいずれかのオプションを指定すると、
項類が2バイト文字または2バイト文字編集のデータ項目が初期化される。
字類が2バイト文字の項目、項類が英数字の項目、項類が英字の項目を自由に混在させてよい。
この規則は、次のように緩められている。受取り側項目の項類が2バイト文字編集であれば、編集が行われる。字類が2バイト文字の項目が含まれるそれ以外の組合わせでは、変換も編集も逆編集も行われない。
この制限は解除された。