多くの文に共通する句と一般規則
以降に説明する各文において、次のような指定が頻繁に出てくる。ROUNDED(四捨五入)指定、ON SIZE ERROR(桁あふれ)指定、
![]() NOT ON SIZE ERROR(桁あふれなし)指定、
NOT ON SIZE ERROR(桁あふれなし)指定、
CORRESPONDING(対応)指定などである。以下に、これらを個々に説明する。
以降の説明の中で、「結果の一意名」という用語を使用する。これは算術演算の結果を入れる一意名を表わす。
ROUNDED指定
小数点の位置をそろえたとき、算術演算の結果の小数部の桁数が結果の一意名の小数部の桁数よりも大きいと、結果の一意名の大きさに応じて切り捨てが発生する。四捨五入が要求されると、あふれる桁の最上位の値が5以上であると、結果の一意名の最下位の桁の絶対値に1が加えられる。
結果の一意名の整数部分の下位がPICTURE文字の "P" を用いて表わされているときには、四捨五入や切り捨ては、実際に記憶場所を割り当てられている部分の右端の整数部に対して行われる。
![]() 浮動小数点数の算術演算においては、ROUNDED指定は注記として扱われる。浮動小数点数の演算結果は、つねに四捨五入される。
浮動小数点数の算術演算においては、ROUNDED指定は注記として扱われる。浮動小数点数の演算結果は、つねに四捨五入される。
ON SIZE ERROR指定
 とNOT ON SIZE
ERROR指定
とNOT ON SIZE
ERROR指定
小数点の位置をそろえたとき、算術演算の結果の絶対値が対応する結果の一意名がとる最大値を超えると、桁あふれ条件が発生する。除数がゼロである除算が行われると、つねに桁あふれ条件が発生する。ON SIZE ERROR指定を指定しなかったときのゼロによる除算の結果はどうなるかわからないので、注意する必要がある。一般に、桁あふれ条件は最終結果に対してだけ適用される。ただし、MULTIPLY(乗算)文およびDIVIDE(除算)文の場合は、中間結果に対しても桁あふれ条件が適用される。
![]() 指数の評価規則から外れると、つねに、算術演算は停止され、桁あふれ条件が発生する。
指数の評価規則から外れると、つねに、算術演算は停止され、桁あふれ条件が発生する。
ROUNDED指定を書くと、四捨五入の後で桁あふれの検査が行われる。その結果桁あふれ条件が発生すると、ON SIZE ERROR指定を指定してあったか否かによって、下記のように処理が分かれる。
ON SIZE ERROR指定がない場合
桁あふれ条件が発生すると、対応する結果の一意名の値はどうなるかわからない。この演算処理が実行される間に、桁あふれ条件が発生しなかった結果の一意名の値が、他の結果の一意名に対して発生した桁あふれ条件の影響を受けることはない。
![]() 算術演算が終了すると、制御は算術文の末尾に移される。NOT ON
SIZE ERROR指定は指定されていても無視される。
算術演算が終了すると、制御は算術文の末尾に移される。NOT ON
SIZE ERROR指定は指定されていても無視される。
除数がゼロの除算の結果は、ON SIZE ERRORを指定していないと、どうなるかわからない。それを避けるためには、CHECKDIVコンパイラ指令と O ランタイム スイッチを使用するとよい。
ON SIZE ERROR指定がある場合
桁あふれ条件が発生すると、桁あふれの影響を受ける結果の一意名の値は変更されない。桁あふれ条件の発生しなかった結果の一意名の値が、この演算処理が実行される間に他の結果の一意名に対して発生した桁あふれ条件の影響を受けることはない。 この演算処理が終了すると、ON SIZE ERROR指定内の無条件命令が実行される。
CORRESPONDING指定を伴うADD(加算)文およびSUBTRACT(減算)文に関しては、個々の演算処理において桁あふれ条件が発生しても、その時点ではON SIZE ERROR指定内の無条件命令は実行されない。個々の加算または減算がすべて終了した後に、ON SIZE ERROR指定内の無条件命令が実行される。
![]() 桁あふれ条件が発生すると、ON SIZE ERROR指定が指定されていても指定されていなくても、NOT
ON SIZE ERROR指定は無視される。
桁あふれ条件が発生すると、ON SIZE ERROR指定が指定されていても指定されていなくても、NOT
ON SIZE ERROR指定は無視される。
![]() ON SIZE ERROR指定とNOT ON SIZE ERROR指定の両方を指定したときに、実行された方の指定の中に制御を明示的に移す文が含まれていないと、必要があればその指定の実行が終わった時点で、その算術文の末尾に制御が暗黙的に移される。
ON SIZE ERROR指定とNOT ON SIZE ERROR指定の両方を指定したときに、実行された方の指定の中に制御を明示的に移す文が含まれていないと、必要があればその指定の実行が終わった時点で、その算術文の末尾に制御が暗黙的に移される。
NOT ON SIZE ERROR指定
![]()
算術演算文を実行したときに桁あふれ条件が発生しなかった場合にNOT ON SIZE ERROR指定が指定されていれば、その中に記述されている無条件命令が実行される。この場合、ON SIZE ERROR指定が指定されていても無視され、その中に記述されている無条件命令は実行されない。
CORRESPONDING指定
以下の説明で、d1とd2という記号を使用する。このd1とd2はそれぞれ別々の集団項目を指す一意名を表わす。d1とd2から1つずつ取った一組のデータ項目は、下記の条件が満たされるとき対応するという。
- d1中のデータ項目およびd2中のデータ項目は、FILLER(無名項目)ではなくデータ名が同じであり、同じように修飾されている。ただし、d1とd2そのものは修飾語に使われていない。
- d1中のデータ項目およびd2中のデータ項目は、少なくとも1つが基本項目である。CORRESPONDINGを伴うMOVE(転記)文に関しては、結果として各データ項目に適用される転記は転記規則に合致している。CORRESPONDINGを伴うADD文およびSUBTRACT文に関しては、両方のデータ項目とも基本数字データ項目である。
- d1およびd2のデータ記述にレベル番号66、77、
 78
78 または88、USAGE IS INDEX句、
が含まれていない。 またはUSAGE IS OBJECT句 - d1またはd2に属するデータ項目で、そのデータ記述中にREDEFINES、RENAMES、OCCURS、USAGE IS INDEX、
USAGE IS
PROCEDURE-POINTER、
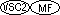 USAGE IS POINTER、
またはUSAGE IS OBJECT
USAGE IS POINTER、
またはUSAGE IS OBJECT の各句が含まれるものは無視される。また、REDEFINES、RENAMES、OCCURS、USAGE IS INDEX、
USAGE IS
PROCEDURE-POINTER、USAGE IS POINTER、またはUSAGE IS OBJECT の各句が含まれるデータ項目の下位に属するデータ項目も同様に無視される。しかし、d1およびd2のデータ記述中にREDEFINES句またはOCCURS句が含まれていてもよい。あるいは、データ記述中にREDEFINES句またはOCCURS句が含まれるデータ項目の下位にd1およびd2が属していてもよい。
d1もd2も、部分参照できない。 - 上記の条件を満たす各データ項目の名前は、暗黙の修飾を使用した後では、一意でなければならない。
算術文
算術文には、ADD、COMPUTE、DIVIDE、MULTIPLY、SUBTRACTがある。これらの文には、下記の共通の特徴がある。
- 作用対象のデータ記述は、同じである必要はない。必要に応じて、データ形式の変換および小数点の位置合わせが行われる。
-
作用対象の合成とは、指定された各作用対象の小数点の位置を合わせて重ね合わせできる、仮想のデータ項目である。
ADD、DIVIDE、MULTIPLY、およびSUBTRACT文の作用対象の合成は、18桁を超えてはならない。
作用対象の合成についての制限はない。
作用対象の重なり
ある文の送出し側項目と受取り側項目とが記憶領域の一部を共有するときで、
![]() 同じデータ記述項目によってまだ定義されていない場合、
同じデータ記述項目によってまだ定義されていない場合、
その文を実行した結果はどうなるかわからない。
![]() 重なりの転記は、MOVE文が使用され、作用対象が部分参照も添え字も使用していない場合にだけ、翻訳時に検出される。コンパイラ指令WARNING"3"を設定してある場合、前方への重なりの転記があると警告メッセージが出される。
コンパイラ指令FLAG"方言"を設定してある場合、その他のタイプであればフラグメッセージが出される。ただし、OSVS以外の"方言"とする。同じ記憶域を共有する項目を送受信する他の操作は、検出されない。
重なりの転記は、MOVE文が使用され、作用対象が部分参照も添え字も使用していない場合にだけ、翻訳時に検出される。コンパイラ指令WARNING"3"を設定してある場合、前方への重なりの転記があると警告メッセージが出される。
コンパイラ指令FLAG"方言"を設定してある場合、その他のタイプであればフラグメッセージが出される。ただし、OSVS以外の"方言"とする。同じ記憶域を共有する項目を送受信する他の操作は、検出されない。
![]() COBOL原始コードの移植性は、原始プログラム内でMOVE文の重なりが起きない時にだけ保証されるが、このCOBOLシステムはこのような文を認めていない。このような文の動作は、BYTE-MODE-MOVE指令の指定により変わる。
COBOL原始コードの移植性は、原始プログラム内でMOVE文の重なりが起きない時にだけ保証されるが、このCOBOLシステムはこのような文を認めていない。このような文の動作は、BYTE-MODE-MOVE指令の指定により変わる。
算術文における複数個の結果
ADD、COMPUTE、DIVIDE、MULTIPLY、SUBTRACTの各文は複数個の答をもつことがある。これらの文は、下記のように書かれたものとして実行される。
- 初期評価部分のすべてのデータ項目を演算処理し、その結果を一時的に記憶し、その一時結果を使用して必要なすべての演算を行い、受取り側項目に答を収める。
- 中間結果を記憶する領域を利用して、一連の作用対象を順々に取り上げて演算を施し、最終的に1つの答を得る。この形の文は、列挙されている複数の作用対象を左から右に順々に取り上げて、別々の文で記述したものとみなされる。
例1:
ADD a, b, c TO c, d (c), e
は、下記のように書いたのと等しい。
ADD a, b, c GIVING temp ADD temp TO c ADD temp TO d (c) ADD temp TO e
例2:
MULTIPLY a(i) BY i, a(i)
は、下記のように書いたのと等しい。
MOVE a(i) to temp MULTIPLY temp by i MULTIPLY temp BY a(i)
ここで、
tempはCOBOLコンパイラによって使用される、中間結果を一時的に記憶する場所である。
矛盾するデータ
字類条件 (前述の字類条件節を参照) の中で参照された場合は除いて、手続き部で参照されたデータ項目の内容が、そのデータ項目のPICTURE句)、
![]() または関数定義
または関数定義
に指定されている字類と合わないと、そのデータ項目を参照した結果はどうなるかわからない。
![]() 数字項目を参照したところ、その項目に文字または無効なデータが含まれていた場合、結果はどうなるかわからない。このような条件は、実行時に検出されてエラーとされる。この動作は、F
ランタイム スイッチの影響を受ける。
数字項目を参照したところ、その項目に文字または無効なデータが含まれていた場合、結果はどうなるかわからない。このような条件は、実行時に検出されてエラーとされる。この動作は、F
ランタイム スイッチの影響を受ける。
![]() 英字項目を参照したところ、その項目に英字でないデータが含まれていた場合、プログラムの実行は続けられるが、結果はどうなるかわからない。
英字項目を参照したところ、その項目に英字でないデータが含まれていた場合、プログラムの実行は続けられるが、結果はどうなるかわからない。
符号付き受取り側項目
算術文またはMOVE文中の受取り側項目が、符号付きの数字または数字編集項目である場合、受取り側項目に符号が転記される。この符号の転記は、数字データの絶対値が切り捨てられたか否かに関係なく行われる。したがって、数値はゼロであるが、符号が負ということが起こり得る。