各国文字定数は、計算機の記憶域で均一サイズの文字として表現される。詳細については、各国文字データ (Unicode) に関する COBOL システムのマニュアルを参照。
書き方 1 の一般形式
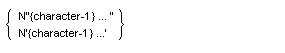
書き方 2 の一般形式
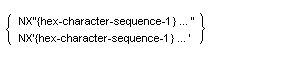
すべての書き方の構文規則
- 定数を区切る区切り文字を除いた各国文字定数の長さは、0 より大きく、160 文字以内とする。
- 文字-1 は、英数字符号化文字集合内の任意の文字とする。これにより、その英数字と各国文字を一致させることができる。
書き方 1 の構文規則
- 開始区切り文字で使用される引用符シンボルに一致する連続した 2 つの引用符文字は、その定数の内容に含まれる引用符文字の単一のオカレンスを表す。連続する 2 つの引用符文字は、開始引用符と同じ符号化文字集合の表現内に含める。
書き方 2 の構文規則
- 各 16 進文字列-1 は、上位のバイトから順に符号化された 4 桁の 16 進数 (2 バイト) である。
すべての書き方の一般規則
- 各国文字定数を区切る区切り文字は、各国文字定数の値には含まれない。
- 各国文字定数は、字類および項類が各国文字に属する。
書き方 1 の一般規則
- 翻訳時の定数の値は、計算機の翻訳時の符号化文字集合で表される文字-1 の文字列となる。
実行時の定数の値は、その定数の翻訳時の値を実行時の値に変換した結果の各国語文字列となる。
書き方 2 の一般規則
- 実行時の定数の値は各国語文字列である。各文字には、1 つだけ含まれる 16 進文字列-1 によって指定されたビット構成が含まれる。