

| 呼び出し可能ソート API | ファイル状態コードテーブル | |
この COBOL システムは、相対、索引、順という 3 つの種類のデータファイル編成を提供します。さらに、順ファイルは 3 つのカテゴリ、レコード順、プリンタ順および行順に分類されます。
この章で扱う内容は、COBOL ファイルの構造の理解を目指すユーザを対象としています。また、この内容はプログラムのデバッグを行う場合にも役に立ちます。ただし、COBOL プログラムからデータファイルを使用する場合は、これらのファイル構造を理解する必要はありません。
注意: バイトストリーム入出力を使用して独自にファイルを処理するのではなく、COBOL 構文や Micro Focus ファイルハンドラ API を使用することをお奨めします。この方法を使用すると、ファイル構造を将来拡張または開発した場合でも、アプリケーションは正常に機能します。
行順ファイル、プリンタ順ファイル、固定長レコードをもつレコード順ファイル、および固定長レコードをもつ相対ファイルには、ファイルヘッダーもレコードヘッダーもありません。
行順ファイルは、システムエディタを使用して作成されたソースまたはテキストファイルを読み取ることができるように設計されています。この場合の構造は、オペレーティングシステムに依存しますが、通常後続の空白文字が削除された可変長レコードを含みます。
行順ファイルでは、ファイルの各レコードは、レコード区切り文字で次のレコードと区切られます。
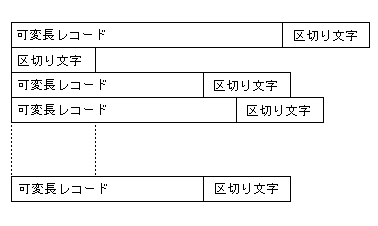
図 14-1: 行順ファイル構造
UNIX システムで作成されたファイルの場合のデフォルトのレコード区切り文字は、単一バイトの x"OA" で指定されたラインフィード文字です。DOS または Windows で作成されたファイルの場合のデフォルトのレコード区切り文字は、バイトペア、 x"ODA" で指定されたキャリッジリターンまたはラインフィード文字です。UNIX でこの COBOL システムを使用して作成されたファイルは、DOS および Windows で読み取ることが可能です (その反対も可能)。
INSERTNULL 構成パラメータを OFF に設定する場合は、どの COMP データにも、x"0A" (レコード区切り文字) の値をもつバイトが含まれないようにします。
プリンタ順は、直接、またはディスクファイルにプーリングしてプリンタに送られるファイル構造です。これらのファイルの構造は、プリンタの操作に必要な内容に影響し、オペレーティングシステムから独立しています。
プリンタ順ファイルは、一連の印刷レコードで構成され、その印刷レコード間にはゼロ以上の垂直位置決め文字 (ラインフィードなど) が含まれます。
印刷レコードは、ゼロ以上の印刷可能文字で構成され、キャリッジリターン (x"0D") で終了します。
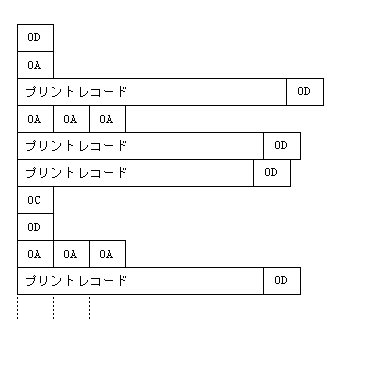
図 14-2: プリンタ順構造
固定長レコードで構成されるレコード順ファイルでは、各レコードはファイル内の前のレコードの直後に続きます。また、各レコードの長さは、最大長レコードと同じ長さになります。
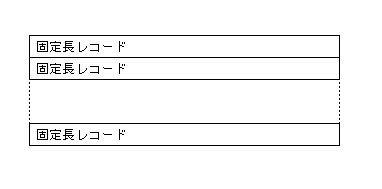
図 14-3: 固定長レコードで構成されるレコード順ファイル
固定長レコードで構成される相対ファイルは、固定長レコードで構成されるレコード順ファイルと同じ構造です。ただし、各レコードの後ろにレコードマーカが付いています。
固定長相対レコードでは、レコードの現在の状態は次のように 1 バイトのマーカで示されます。
| マーカ(16進数)
|
説明 |
|---|---|
| 0A | レコードは存在します。 |
| 00 | レコードは削除されているか書き込まれていません。 |
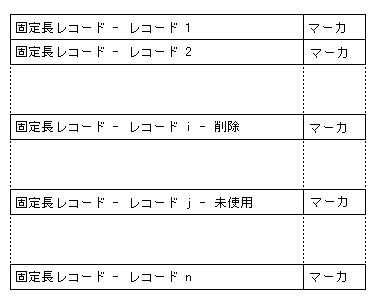
図 14-4: 固定長レコードで構成される相対ファイル
ファイルヘッダーは、ファイルの開始位置にある 128 バイトのブロックです。索引ファイル、可変長レコードで構成されるレコード順ファイルおよび可変長レコードで構成されるすべての相対ファイルに、ファイルヘッダーが含まれます。また、これらのファイルの各レコードの前には、2 または 4 バイトのレコードヘッダーが付いています。
注: ファイルヘッダーとレコードヘッダー情報は、この COBOL システムにより維持されており、変更することはできません。
すべての可変構造ファイルの最初のレコードは、ファイルヘッダーと呼ばれるシステムレコードです。このヘッダーの長さは通常 128 バイトで、次の形式をとります。
| オフセット | サイズ | 説明 |
| 0 | 4 | ファイルヘッダーの長さ。最初の 4 ビットは常に 3 (バイナリの 0011) に設定され、これがシステムレコードであることを示します。残りのビットには、ファイルヘッダーレコードの長さが含まれます。最大レコード長が 4095 バイト未満の場合は、長さが 126 になり、次の 12 ビットに格納されます。それ以外の場合は、長さが 124 になり、次の 28 ビットに格納されます。そのため、最大レコード長が 4095 バイト未満のファイルの場合は、このフィールドに x"30 7E 00 00" が含まれます。それ以外の場合は、このフィールドに、x"30 00 00 7C" が含まれます。 |
| 4 | 2 | アドオン製品で使用するデータベース連続番号 |
| 6 | 3 | 一貫性フラグ。索引ファイルのみ。ヘッダーの読み取り時にこの値がゼロ以外の場合は、ファイルが破損していることを示します。 |
| 8 | 14 | 作成日時は YYMMDDHHMMSSCC 形式で表されます。索引ファイルのみ。 |
| 22 | 14 | 予約フィールド |
| 36 | 2 | 予約フィールド。値は 62 の 10 進数、x"00 3E" となります。 |
| 38 | 1 | 使用しません。ゼロに設定します。 |
| 39 | 1 | 編成 1=順 2=索引 3=相対 |
| 40 | 1 | 使用しません。ゼロに設定します。 |
| 41 | 1 | データ圧縮ルーチン番号 0 = 圧縮なし 1 = CBLDC001 2-127 = 内部使用のために予約済み 128-255 = ユーザ定義の圧縮ルーチン番号 |
| 42 | 1 | 使用しません。ゼロに設定します。 |
| 43 | 1 | 索引ファイルのみ (索引ファイルの種類)。索引ファイルの種類の一覧については、『索引ファイル』を参照してください。 |
| 44 | 4 | 予約フィールド |
| 48 | 1 | レコードモード 0 = 固定形式 1 = 可変形式 索引ファイルの場合は、.idx ファイルのレコードモードフィールドが優先されます。 |
| 49 | 5 | 使用しません。ゼロに設定します。 |
| 54 | 4 | 最大レコード長。例えば、最大レコード長が 80 文字の場合は、このフィールドに x"00 00 00 50" が含まれます。 |
| 58 | 4 | 最小レコード長。例えば、最小レコード長が 2 文字の場合は、このフィールドに x"00 00 00 02" が含まれます。 |
| 62 | 46 | 使用しません。ゼロに設定します。 |
| 108 | 4 | ファイルを作成する索引ファイルハンドラ用のバージョンおよびビルドデータ。索引ファイルのみ。 |
| 112 | 16 | 使用しません。ゼロに設定します。 |
可変構造ファイルの各レコードの前には、2 または 4 バイトのレコードヘッダーが付いています。このヘッダーの最初の 4 ビットは、レコードの状態を示します。例えば、0100 の値は、このレコードが標準のユーザデータレコードであることを示します。
レコードヘッダーの残りの部分には、レコード長が格納されます。最大レコードサイズが、4095 バイト (レコードヘッダーを除く) 未満のすべてのファイルでは、レコードヘッダーの長さは、 2 バイトです。他のすべてのファイルでは、レコードヘッダーの長さは 4 バイトです。
各レコードのレコードヘッダーは、このファイルタイプ用のデータ整列値の正確な倍数のアドレスから開始されます (データ整列値の詳細については、『索引ファイル』を参照してください)。そのため、レコードの後には、 n 個以下の埋め込み文字 (通常は空白文字) が付いています。これらの埋め込み文字は、レコード長には含まれません。
| 最初の 4 ビット | レコードタイプ |
| 1 (0001) | システムレコード。データファイルの重複オカレンスレコードを示します。 |
| 2 (0010) | 削除されたレコード (空き領域リストを使って再使用可能) |
| 3 (0011) | システムレコード |
| 4 (0100) | 標準のユーザデータレコード |
| 5 (0101) | 縮小されたユーザデータレコード (索引ファイルのみ)。ヘッダーの長さで示されるデータの直後の領域は、データレコードの終わりとすべての埋め込み文字から次のレコードヘッダーの開始までの長さを示します。この情報は、2 または 4 バイトフィールドのどちらかに格納されます (詳細については、『索引ファイル』の項を参照してください)。 |
| 6 (0110) | ポインタレコード (索引ファイルのみ)。レコードヘッダーの後に続く最初の n バイトには、ユーザデータレコードの場所に対するファイル内のオフセットが格納されます。この n は索引ファイルタイプのファイルのポインタサイズです (詳細については、『索引ファイル』を参照)。 |
| 7 (0111) | ポインタレコードで参照されるユーザデータレコード |
| 8 (1000) | ポインタレコードで参照される縮小されたユーザデータレコード |
可変長レコードで構成されるレコード順ファイルでは、書き込まれた各レコードの前に、レコード長を含むレコードヘッダーが付いています。
次のレコードが 4 バイトの境界で開始されるように、レコードの後ろには最大 3 文字の埋め込み文字が続きます。
このファイルには、標準のファイルヘッダーレコードが含まれます。
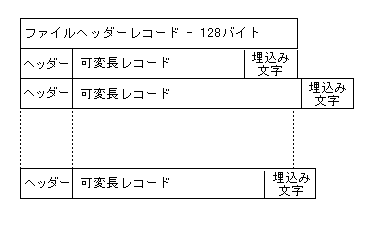
図 14-5: 可変長レコードで構成されるレコード順ファイル
可変長レコードで構成される相対ファイルは、基本的な可変構造に従いますが、各レコードは、固定長スロット、最大長のレコードとして定義されているスロットの長さ、およびヘッダーと終了記号文字に分けられます。
各レコードのレコードヘッダーには、物理固定長スロットの長さではなく、書き込まれる論理レコードの長さが格納されます。
レコードの現在の状態は、次のように 2 バイトのマーカーで示されます。
| マーカー (16 進) |
説明 |
|---|---|
| 0D0A | レコードは存在します。 |
| 0D00 | レコードは削除されているか書き込まれていません。 |
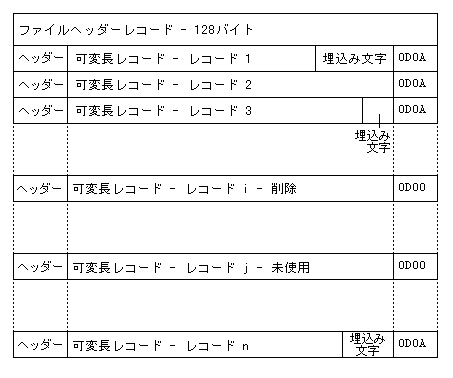
Figure 14-6: 可変長レコードで構成される相対ファイル
索引ファイルは、次の内容で構成されます。
ファイルヘッダーには、ファイルに関する情報が格納され、最初の空き領域レコードとキー情報レコードを示します。
空き領域レコードは、索引ファイルとデータファイル内の空きレコードのリストを保守するために使用します。
キー情報レコードには、ファイルに定義されているすべてのキーの詳細が含まれます。また、キーごとに、そのルート索引ノードを示します。
定義されているキーごとに、完全で独立した索引が作成されます。索引ノードレコードは、実際のキー値を格納する索引ノードレコードのツリーで構成されます。ノード内のすべてのキー値は、従属の索引ノードレコードまたはそのキーに関連する実際のデータレコードを示します。
索引ファイルのレコードの長さは、索引ノード、ファイルヘッダーまたはキー情報レコードのどれでも常に同じです。レコードのサイズは、ファイルの作成時に決定され、後で変更することはできません。
次に示す表は、使用できるさまざまな種類の索引ファイルと、それらのファイルがサポートする機能を示しています。
表 14-1: 索引ファイル - サポートされる機能
| 論理的なファイルのサポート (4GB未満) | 複数の重複キーをもつファイルの高速更新 | 重複キー値の最大オカレンス | 可変長レコードおよび圧縮のサポート | 別の索引ファイル | |
| IDXFORMAT"1" | なし | なし | 65535 | なし | あり |
| IDXFORMAT"2" | なし | なし | 65535 | なし | あり |
| IDXFORMAT"3" | なし | なし | 65535 | あり | あり |
| IDXFORMAT"4" | なし | あり | 4G | あり | あり |
| IDXFORMAT"8" | あり | あり | 4G | あり | なし |
表 14-2: 索引ファイル - 物理特性
| 重複オカレンスレコード | データレコード整列 | ファイルポインタサイズ (バイト数) | 剰余長フィールド | レコードヘッダーを含む索引ノード | |
| IDXFORMAT"1" | なし | 1 | 4 | 該当なし | なし |
| IDXFORMAT"2" | なし | 1 | 4 | 該当なし | なし |
| IDXFORMAT"3" | なし | 4 | 4 | 2 | なし |
| IDXFORMAT"4" | あり | 4 | 4 | 2 | なし |
| IDXFORMAT"8" | あり | 8 | 6 | 4 | あり |
ファイルヘッダーは、索引ファイル内のオフセット 0 に位置します。次に示すフィールド以外、最初の 128 バイトは標準の可変構造ファイルヘッダーと同じです。
| オフセット | サイズ | 説明 |
| 0 | 4 | ファイルヘッダーの長さ |
| 39 | 1 | 常に索引編成の値 2 を含みます。 |
| 62 | 14 | 常にゼロを含みます。 |
| 76 | 1 | 予約フィールド。4 に設定します。 |
| 120 | 8 | 索引ファイルの論理終了のオフセット |
ファイルヘッダーの残りの部分には、次のフィールドがあります。
| オフセット | サイズ | 説明 |
| 128 | 8 | データファイルの論理終了のオフセット |
| 136 | 1 | 値 2 |
| 137 | 1 | 値 2 |
| 138 | 1 | 値 4 |
| 139 | 1 | 値 4 |
| 140 | 2 | ファイルに定義されているキー数を含みます。 |
| 142 | 1 | 値 0、または重複オカレンスレコードが存在する場合は 1。詳細については、『索引ファイルの種類』の項を参照してください。 |
| 143 | 1 | 値 2 または 4。重複が許可されている索引のオカレンス番号に使用するバイト数。 |
| 144 | 8 | 最初のキー情報レコードのオフセット |
| 152 | 8 | データファイルの空き領域レコードのオフセット。固定形式のファイルの場合は、索引空き領域レコードと同じ形式の索引ファイルのレコードになりますが、アドレスはデータファイルの空きレコードを示します。可変形式のファイルの場合は、データ空き領域レコードのデータファイルのアドレスになります。このレコードは、索引空き領域レコードに対して異なる構造を持ちます。 |
| 160 | 8 | 索引ファイル内の最初の空き領域レコードのオフセット。 |
| 168 | 4 | 値ゼロ |
| 172 | 4 | 索引ファイルレコード長 (ノードサイズ) |
| 176 | 8 | 値ゼロ |
| 184 | 328 840 3912 |
予約済みフィールド。値ゼロ。ノードサイズは 512。 予約済みフィールド。値ゼロ。ノードサイズは 1024。 予約済みフィールド。値ゼロ。ノードサイズは 4096。 |
空き領域レコードは、索引ファイルまたはデータファイル (固定長ファイルのみ) の空きレコードの場所を示します。必要に応じてサイズと構造が同じ継続レコードが作成され、それぞれ次の継続レコードを示します。
最初の空き領域レコードは、ファイルヘッダーで示されます。
空き領域レコードには、次の内容が含まれます。
| サイズ | 説明 |
| 2 | レコードヘッダー。索引ノードにレコードヘッダーがある場合にのみ存在します (『索引ファイル』の項を参照)。 |
| 2 | ビット 15 セキュリティフラグ。値は、後続のセキュリティフラグの値と一致させる必要があります。 ビット 14~0 このレコードの開始位置に相対的な、最後の空き領域アドレスエントリの終わりを示すポインタ |
| file-pointer-size | 空き領域継続レコードのオフセット。その後に続く継続レコードがない場合はゼロになります。 |
| file-pointer-size ... file-pointer-size |
索引ファイルの空きレコードのオフセット ... 索引ファイルの空きレコードのオフセット |
| 2 | ビット 15 セキュリティフラグ。値は、先行するセキュリティフラグの値と一致させる必要があります。 ビット 14~0 予約済みフィールド。値は x"7F" です。 |
注: file-pointer-size のサイズは、索引ファイルの種類によって異なります。詳細については、『索引ファイル』の項を参照してください。
キー情報レコードは、ファイル内で使用するすべてのキーの物理特性を記述します。この情報には、各キーの長さ、データレコード内のキーが定義される場所、重複が許可されているかどうかなどがあります。キー情報のレコード構造の中には、副構造体であるキーブロックがあります。キーブロックは、定義されているキーごとに作成されます。最初のキーブロックは、常に主キーを記述します。次に続くキーブロックは、ファイルの作成時に指定した順序で副キーを定義します。キー情報レコードが、定義されているすべてのキーのキーブロックを格納できる大きさである場合は、同じサイズの継続レコードが作成され、各レコードは、すべてのキーが定義されるまで次のレコードを示します。
キー情報レコードには、次のフィールドがあります。
| サイズ | フィールドの説明 |
| 2 | レコードヘッダー。索引ノードにレコードヘッダーがある場合にのみ存在します。詳細については、『索引ファイル』の項を参照してください。 |
| 2 | ビット 15 セキュリティフラグ。値 0。 ビット 14~0 このレコードの開始に相対的な、レコードの最後のキーブロックエントリの終わりを示すポインタ。 |
| file-pointer-size | 継続レコードのアドレス。その後に続く継続レコードがない場合はゼロになります。 |
| n ... n |
主キーのキーブロック。 ...ファイルの副キーごとに 1 つずつあります。 キーブロック。 |
| 1 | 予約済みフィールド。値は x"FF" です。 |
| 1 | 予約済みフィールド。値は x"7E" です。 |
IDXFORMAT"8" 以外のすべての種類の索引ファイルについて、キーブロックには次のフィールドが含まれます。
| サイズ | フィールドの説明 |
| 2 | このエントリの長さ (バイト数) |
| 4 | このキーのルート索引ノードレコードのアドレス |
| 1 | キー圧縮 ビット 2 後続空白文字の圧縮 ビット 1 先行文字の圧縮 ビット 0 重複の圧縮 |
| 5 ... 5 |
キー構成要素ブロック。 ...キーを分割する場合は、構成要素ごとに 1 つのブロックになります。 キー構成要素ブロック。 |
IDXFORMAT"8" ファイルの場合は、キーブロックに次のフィールドが含まれます。
| サイズ | フィールドの説明 |
| 2 | このエントリの長さ (バイト数) |
| 1 | スパースキー文字 |
| 13 | 予約済みフィールド |
| 1 | キー圧縮 ビット 3 後続ヌルの圧縮 ビット 2 後続空白文字の圧縮 ビット 1 先行文字の圧縮 ビット 0 重複の圧縮 |
| 1 | キーフラグ ビット 6 重複許可 ビット 1 スパースキー |
| 6 ... 6 |
キー構成要素ブロック。 キーを分割する場合は、構成要素ごとに 1 つのブロックになります。 キー構成要素ブロック。 |
IDXFORMAT"8" 以外のすべての種類の索引ファイルについて、キー構成要素ブロックには、次のフィールドが含まれます。
| サイズ | フィールドの説明 |
| 2 | ビット 15 重複許可フラグ。このフラグを設定すると、重複が許可されます。ビット 14~0 構成要素の長さ (バイト数)。 |
| 2 | 0 から開始する、データレコード内の構成要素のオフセット |
| 1 | 構成要素の種類。値はゼロです。 |
IDXFORMAT"8" ファイルの場合は、キー構成要素ブロックに次のフィールドが含まれます。
| サイズ | フィールドの説明 |
| 2 | 構成要素の長さ (バイト数)。 |
| 2 | 0 から開始する、データレコード内の構成要素のオフセット。 |
| 1 | 構成要素フラグ ビット 6 降順 |
| 1 | 構成要素の種類 ビット 7 数値 ビット 6 符号付き ビット 5~0 数値でない場合は、次のようになります。 0 英数字 数値の場合は、次のようになります。 h"00" DISPLAY (SIGN TRAILING INCLUDED) h"01" DISPLAY (SIGN TRAILING SEPARATE) h"02" DISPLAY (SIGN LEADING INCLUDED) h"03" DISPLAY (SIGN LEADING SEPARATE) h"20" COMP h"21" COMP-3 h"22" COMP-X h"23" COMP-5 h"24" FLOAT |
定義されたキーごとに、完全な独立した索引が作成されます。この索引ノードレコードは、索引ノードレコードのツリーで構成されます。各索引ノードレコードには、索引ファイルに書き込まれているデータレコードに関連する実際のキー値が含まれます。ノード内のすべてのキー値は、従属の索引ノードレコードまたは、リーフノードの場合は、キーに関連するデータレコードを示します。
最上位レベルのノードレコードは、ルートと呼ばれます。
デフォルトのノードサイズは、1024 バイトですが、ファイルに定義されている最大キーサイズによって変更される場合もあります。最大キーが 238 バイトよりも大きい場合は、ノードサイズは 4096 バイトになります。
注: XFHNODE 環境変数を、512、1024 (デフォルト) または 4096 バイトに設定して、デフォルトのノードサイズを変更することができます。ただし、XFHNODE を 512 に設定し、キーの最大値が 120 バイトを超えている場合は、XFHNODE の値が 1024 に変更されます。また、XFHNODE を 512 または 1024 に設定し、キーの最大値が 248 を超える場合は、XFHNODE の値は 4096 に変更されます。XFHNODE の値は、ファイルの作成時にのみ設定できます。既存のファイルのノードサイズを変更することはできません。
索引ノードレコードには、次のフィールドがあります。
| サイズ | フィールドの説明 |
| 2 | ビット 15 セキュリティフラグ。この値は、後続のセキュリティフラグの値と一致している必要があります。 ビット 14~0 このレコードの開始に相対的な、レコードの最後のキー値ブロックの終わりを示すポインタ。 |
| n ... n |
キー値ブロック ... キー値ブロック |
| 1 | 索引番号。 値は、同じ索引ツリーに属するすべてのノードについて同じです。主キーの場合は、ゼロが含まれます。 |
| 1 | ビット 7 セキュリティフラグ。この値は、先行するセキュリティフラグの値と一致している必要があります。 ビット 6~0 このノードのレベル。リーフノードはレベル 0 です。 |
キー値ブロックには、次のフィールドが含まれます。
| サイズ | フィールドの説明 |
| 1 | 先行文字の圧縮が有効な場合にのみ存在します。このフィールドには、前のキーと同じ先行文字のカウントが含まれます。この値は、ノードの最初のキーについては常に 0 になります。 |
| 1 | 後続空白文字の圧縮を有効にする場合にのみ存在します。このキー値の後続空白文字のカウントが含まれます。 |
| n | キー値 |
| duplicate-occurrence | オプション。重複オカレンス番号。詳細については、『索引ファイル』の項を参照してください。このフィールドは、このキーに重複が許可されている場合にのみ存在します。このフィールドには、重複オカレンスカウントが含まれます。格納されている重複する最初のキーでは、このフィールドは 1 に設定されます。2 番目の重複ではこのフィールドは 2 に設定され、その後も同様に設定されます。 |
| file-pointer-size | MSB 重複キーの圧縮が有効な場合は、予約済みフィールドになります。次のキー値ブロックがこのキーの重複である場合に設定します。 残りの部分 リーフノードである場合は、データファイル内のデータレコードのアドレスになります。それ以外の場合は、索引ファイルの従属索引ノードレコードのアドレスになります。 |
索引ファイルのデータファイル部分には、すべてのデータレコードが格納されています。
データファイルの空きレコードに関する情報が保守されるため、レコードを削除して作成された領域を再利用することができ、ファイルサイズが急激に増大することがなくなります。
固定形式の索引ファイルでは、この情報は、索引ファイルの空き領域レコードに格納されます。このレコードの構造は、索引空き領域レコードの構造と同じですが、アドレスはデータファイルレコードを示しています。
可変形式の索引ファイルでは、情報がデータファイルのシステムレコードに格納されます。レコードサイズはすべて、データレコード整列サイズの倍数になります。スロットの長さごとに、空いている長さのすべてのスロットに対して連鎖が維持されます。どの長さについても、連鎖の開始はデータファイルのデータ空き領域レコードに保持されます。このシステムレコードは、ファイルの最大スロット長、または圧縮した場合は最大圧縮長 (レコードの長さは圧縮すると長くなる場合があります) と常に同じです。レコード各空きスロットは、ヘッダーの後の最初の n バイトに、同じ長さの次の空きスロットのアドレスを格納します。連鎖の最後のスロットについては、このアドレスにゼロが格納されます。
データ空き領域レコードには、次のフィールドがあります。
| オフセット | サイズ | フィールドの説明 |
| 0 | 2 または 4 | レコードヘッダー |
| 2 または 4 | 4 | 長さが 8 バイトの最初の空きデータスロットのオフセット |
| 6 または 8 ... n |
4 | 長さが 12 バイトの最初の空きデータスロットのオフセット ... 最大長の最初の空きデータスロットのオフセット |
Copyright © 2002 Micro Focus International Limited. All rights reserved.
本書、ならびに使用されている固有の商標と商品名は国際法で保護されています。
| 呼び出し可能ソート API | ファイル状態コードテーブル | |