ここでは、Enterprise Server でアプリケーションを実行したときに発生する一般的な問題の診断方法、およびその解決策について説明します。
トラブルシューティングでは、問題が発生したときのエンタープライズサーバの状態、および問題の原因となった事象に関する情報を可能な限り集めることが最も重要です。
情報収集のために利用する診断データには次のものがあります。
問題が実際に発生した場合には、現在のログファイル、ダンプ、およびトレースに加え、さまざまなファイル、ディレクトリ、および領域の内容、オペレーティングシステムのいくつかのツールの出力も収集する必要があります。問題が発生する前にデータを収集するための機構を機能させておく必要があります。これにより、問題の発生時のデータを簡単に取得できます。運用中のシステムの場合は、問題のエンタープライズサーバのサービスを復旧しクライアントが使用できるようにしてから、取得したデータの分析を行うことをお奨めします。また、オペレーティングシステムをリブートし、エンタープライズサーバを起動した直後の正常な状態でのデータも収集しておくことをお奨めします。問題が発生したときに取得したデータと比較するために、正常な状態で取得したデータを保存しておく必要があります。
また、エンタープライズサーバがクライント要求と ESMAC からの要求に応答しているかも確認する必要があります。応答がない場合は、通信プロセス (MFCS) に問題があります。
エンタープライズサーバは、通常、/var/mfcobol/es/es-name/console.log コンソールログファイルにメッセージを記録します。エンタープライズサーバの起動時に、既存の console.log ファイルの名前が console.bak に変更され、既存の console.bak ファイルが削除されます。データ収集では、console.log と console.bak ファイルの両方を収集の対象にする必要があります。これらのファイルを必ず安全な場所にコピーしてから、エンタープライズサーバを再起動してください。
Directory Server は、通常、/var/mfcobol/logs/journal.dat ジャーナルにイベントを記録します。最新のエントリは、Enterprise Server Administration の Web インターフェイスのページにも表示されます。
Enterprise Server Administration の「構成オプション」ページで、最大ファイルサイズ、表示するエントリ数、およびロギングのレベルを変更できます。ジャーナルのサイズが、設定されている最大ファイルサイズに達すると、最も古いエントリが最新のエントリで上書きされます。トラブルシューティングの場合は、最大ファイルサイズを 256 KB 以上に設定してください。
ロギングには、次の 3 つのレベルがあります。
トラブルシューティングの場合は、「すべての情報」に設定してください。
通信プロセス (MFCS) は、通常、/var/mfcobol/es/es-name/log.html 通信プロセスログファイルにメッセージを記録します。複数の通信プロセスが実行している場合は、各メッセージの先頭の日時に、[2] のように角かっこでインスタンス識別子が続きます。
デフォルトでは、管理者によって削除されるまで連続的に増大するログファイルは 1 つのみです。mf-server.dat ファイルを使用すると、複数のログファイルを切り替えて使用したり、ロギングのレベルを変更したりできます。mf-server.dat ファイルは、通常では、$SYSTEMROOT (Windows) または $COBDIR/etc (UNIX) に作成されます。このファイルでは、角かっこで囲まれたセクションタグと、その後に name=value の組み合わせが続く ini-file 形式を使用します。
ログファイルの切り替えのために、MFCS は log-1.html、log-2.htmlなどの名前の付いた複数のログファイルを使用します。ログファイルのサイズが設定されているサイズに達すると、MFCS は次のファイルを使用します (このファイルがすでに存在する場合はまず削除します)。ログファイルの数が設定されている数に達すると、log-1.html ファイルに戻ります。この切り替えにより、全体のログサイズが特定のサイズを超えることはなくなります。
構文は、次のとおりです。
[logging] files=number-of-files filesize=maxsize dscontrol=none|standard|all dirsvc=none|unusual|processing|not-found|all
パラメータの指定はすべてオプションですが、複数のログファイルの切り替えを行う場合は、files と filesize の両方を設定し、files には 2 以上の値を設定する必要があります。こられのパラメータは、上記で示したログファイルの切り替えの設定に使用します。両方のパラメータを設定すると、MFCS に必要なログファイルの合計サイズが files×filesize (概算) を超えなくなります。パラメータを、次に示します。
ログファイル数を指定します。
files=number-of-files
ログファイルの最大サイズ (KB)
filesize=maxsize
制御メッセージのロギングレベル。通常、制御メッセージは Directory Server (MFDS) によって出力されますが、他のソースから出力することもできます。制御メッセージでは、構成の更新などの特定のアクションを実行するように MFCS に指示します。
dscontrol=none|standard|all
| none | 制御メッセージは記録しません。 |
| standard | MFCS の構成または状態の更新を指示する制御メッセージを記録します。エンタープライズサーバが動作しているかを確認するために MFDS が使用する KEEPALIVE probe メッセージなどの、情報を要求するのみのメッセージは記録しません。 |
| all | すべての制御メッセージを記録します。 |
| デフォルト: | standard |
MFCS が Directory Server リポジトリの問い合わせまたは更新を試みる際のロギングレベル。このオプションの設定は、構成の問題を診断する場合に役立ちます。
dirsvc=none|unusual|processing|not-found|all
| none | Directory Server のアクティビティに関する情報を記録しません。 |
| unusual | オブジェクト名の重複など、構成に問題がある可能性を示す、通常と違う結果のみ記録します。 |
| processing | 正常な処理の進捗に関するメッセージも記録します。これは、デフォルト設定です。 |
| not-found | not-found ステータスが返された検索に関するメッセージも記録します。MFCS では必要のないオプションの構成項目が削除されることを想定しているため、通常ではこれらのメッセージは記録されませんが、場合によっては、not-found が返された検索をすべて記録することで、構成の問題の診断に役立つことがあります。 |
| all | 通常の MLDAP アンバインドオペレーションなどの、さらに多くの情報も記録します。 |
| デフォルト: | processing |
運用システムでは、診断機能のいくつかを必ず有効にすることをお奨めします。これにより、予期しない問題が発生した場合でもその診断が可能となります。診断ではリソースが消費されるため、問題を特定する機能とパフォーマンスの間で常にリソースの競合が発生します。問題が起きた状況を再発生させるか、または問題が発生した時点で診断をオンにして問題が再発生するのを待つのではなく、問題が初めて発生したときに診断が機能するようにしておくことの重要性を見極める必要があります。最低でも次の診断のレベルに設定しておくことをお奨めします。
また、タスク制御、記憶域制御、およびアプリケーションコンテナの構成要素に対してトレースを有効にする必要がある場合があります。
トレースの設定および内部でトリガーされるダンプの設定は、「サーバの編集 > 診断」ページ、またはESMAC の「制御」ページで行います。「サーバの編集 > 診断」ページのトレースフラグと同等である、ESMAC の「制御」ページのトレースフラグは次のとおりです。
| 「サーバの編集 > 診断」ページ | ESMAC の「制御」ページ |
|---|---|
| アプリケーション | API |
| タスク制御 | KCP |
| 記憶域制御 | SCP |
| アプリケーションコンテナ | RTS |
「サーバの編集 > 診断」ページで指定した設定は、ESMAC の「制御」ページで指定した設定よりも優先されます。
システムまたはトランザクションが異常終了したときに作成されたダンプは、内部的にトリガーされたダンプです。「制御」ページでこれらのダンプを選択している場合は、異常終了が発生するとこれらのダンプが作成されます。外部的にトリガー、つまり、コマンドを発行してダンプを取ることもできます。外部的にトリガーしてダンプを取得するには、次のいくつかの方法があります。
casdump コマンドには柔軟性があります。最初は、/d オプションを指定しないでコマンドを次のように実行します。この場合、共有メモリはロックされません。
casdump /res-name
このオプションなしで実行すると、エンタープライズサーバが記憶連鎖の追跡やダンプ中に変更される共有メモリによる障害の原因になる場合があります。「/d」オプションなしでコマンドを実行することには、まだ価値があります。それは、連鎖の追跡やブロックのフォーマットを開始する前にブロックの先頭として、共有メモリをすべてダンプするからです。
コマンドがハングアップした場合は、/d オプションを指定してコマンドを再度実行します。
casdump /res-name /d
エンタープライズサーバが共有メモリをロックしたまま異常終了すると、このコマンドは失敗する可能性があります。
問題の調査のためにダンプファイルを弊社に送付された場合、弊社では /f オプションを指定してこのコマンドを実行するよう依頼する場合があります。このオプションを指定すると、共有メモリの使用に関する詳細情報を提供する FAQE (free area queue element) チェインがダンプされます。
外部的にトリガーしたダンプでは、/d オプションを指定した場合はダンプ X データセット casdumpx.rec に、/d オプションを指定しない場合は現在のダンプデータセット casdumpa.rec または casdumpb.rec にデータが書き込まれます。
データの取得では、少なくとも次のものを取得する必要があります。
ps -ef
ipcs -a
lsof
このコマンドはサードパーティの UNIX ツールサプライヤから入手できます。
注:
データ取得プロセスは非破壊的なプロセスなので、システムの運用に影響を与えることはありません。また、非ブロッキングであるため、問題があるシステムで完了する見込みのないタスクの完了は待ちません。
データ取得を実行する場合は、通信プロセス (MFCS) が動作していることを確認する必要があります。通信サーバが動作している場合は、通信サーバが現在実行しているタスクを確認できます。手順は次のとおりです。
http://hostname:port/MF_KEEPALIVE
hostname は手順 1 で書き留めたホスト名 (または IP アドレス)、port は手順 2 で書き留めたポート番号です。
MFCS が正常に動作している場合は、次のような応答が表示されます。
Server=ESDEMO ServerType=GKC Version=1.2.5 Status=Started
複数の通信プロセスが実行している場合は、それぞれをこの方法で確認できます。手順 2 で記録されたそれぞれのポート番号は、通信プロセスと一致します。サーバが無効とされている通信プロセスは、確認する必要がありません。
障害は、次のカテゴリに分類されます。
障害を分類するための手がかりとなる最初の情報には次のものがあります。
これらの情報と外部的な症状を考慮することで、上記で示した障害の種類のどれに相当するかを判断することができます。
次に、アプリケーションの問題か、エンタープライズサーバのインフラストラクチャの問題かを調べます。
異常終了以外のアプリケーション障害は多くの場合、アプリケーションの問題です。アクティブなトレースデータセットおよびダンプ X データセット (casdumpx.rec) 内のシステムトレーステーブルを調べて、障害が発生する前のアプリケーションのアクティビティを特定します。
アプリケーションが異常終了した場合は、アプリケーションの問題の場合とエンタプライズサーバのインフラストラクチャの問題の両方の可能性があります。アクティブなダンプデータセットに RTS エラーダンプがあるかを調べます。ある場合は、RTS エラーを調べて問題を分類します。どのモジュールに問題が起きているかによって、問題の原因がアプリケーションか、エンタープライズサーバのインフラストラクチャかがわかります。
システムコンソールログにシステムシャットダウンの原因を示すメッセージがあるかを調べて、問題を切り分けます。
ループしているプロセスの名前を調べて障害を分類します。ループしているプロセスがサービス実行プロセス (Windows の場合は cassi、UNIX の場合は cassi32 ですが、以降では cassi とする) の場合は、ループはエンタープライズサーバのサブシステム内かアプリケーション内のどちらかで発生しています。アクティブなトレースデータセットおよびダンプ X データセット内のシステムトレーステーブルを調べて、最後に実行されていたモジュールを特定します。ループしているプロセスがアプリケーションの場合は、次に障害が発生した場合に詳細な情報を取得できるように、そのプロセスに対して FaultFind を使用することを検討してください。
ループしているプロセスは cassi ですが、最後に実行されていたモジュールがアプリケーションの一部でない場合、またはループしているプロセスが cassi でない場合は、弊社のサポート担当にお問い合わせください。
エンタープライズサーバがすべてのクライアント要求に応答しないのか、特定のクライアント要求にのみ応答しないのかを調べます。
アプリケーションでリソースの競合が発生している可能性があります。また、サービスリスナーでエラーが発生した可能性があります。
「現ステータス」カラムの [詳細] をクリックして、エンタープライズサーバの「詳細」ページの「要求サービス実行プロセス数」で数値を指定し、[更新] をクリックして、動的に増加するサービス実行プロセス数を試行できます。新しいプロセスは、少し遅れた後にリストに表示されます。表示された場合は、問題の症状がなおも現れている場合でも、共有メモリはロックされてなく、エンタープライズサーバがあるレベルでなおも機能していることを示しています。
ダンプ X データセットを調べて、アクティブなサービス実行プロセス (cassi プロセス) の数を確認します。各サービス実行プロセスについてディスパッチ制御ブロックを調べます。すべてのサービス実行プロセスが現在 1 つのトランザクションに従事しているか確認します。従事しているトランザクションが各 cassi プロセスで同じかどうか、各 cassi プロセスが最後に実行したコマンドが同じかどうか確認します。このどちらかの状況にあてはまる場合は、次の可能性があります。
別の原因としては、サーバの共有メモリがロックされていることが考えられます。共有メモリがロック状態にあるかを確認するには、ダンプ X データセットに格納された最後のトレースエントリの日時とダンプの日時を比較します。これらの 2 つの日時に大きな相違がある場合には、共有メモリがロックされている可能性が高くなります。共有メモリがロックされていない場合は、サーバが待機しているイベントを特定します。共有メモリがロックされている場合は、共有メモリにロックされた状態のプロセスを特定します。
また、別の原因として、アプリケーションやエンタープライズサーバの問題によるエラーではなく、オペレーティングシステムのプロセス制限数を超えてエンタープライズサーバのプロセスを実行しようとしたことが考えられます。 詳細は、『プロセスの制限』の節を参照してください。
エンタープライズサーバを診断サーバとして問題の調査のみの目的で使用すると、診断機能を最大限に利用できます。このように診断サーバを使用すると、問題が発生した運用中のサーバからの確実なダンプおよびトレースデータを表示できます。
診断サーバはエンタープライズサーバの 1 つです。ESMAC で利用できる診断機能は、他のサーバで利用できる機能とまったく同じです。唯一異なる点は、それ自身が診断を行わないように構成することです。 これにより、別のサーバからの診断情報を処理する用途で使用できます。図 11-1 に、診断サーバの推奨する構成を示します。
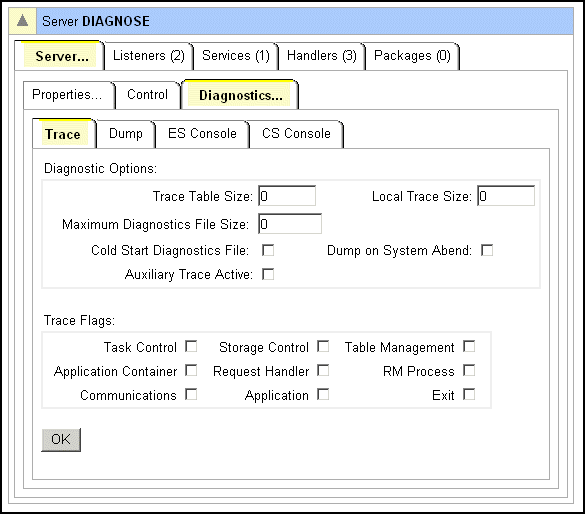
図 11-1: 診断サーバの構成
問題が発生したサーバから収集したデータを診断サーバにコピーしてから収集したデータの診断を開始します。収集したデータとログファイルを診断サーバにコピーするコマンドを次に示します。ここでは、現在のディレクトリが、問題が発生したエンタープライズサーバのディレクトリであることを想定しています。
cp *.rec /var/mfcobol/es/diagnostics-server-name cp console.log /var/mfcobol/es/diagnostics-server-name/console.aux cp console.bak /var/mfcobol/es/diagnostics-server-name/console.bak
必要なデータを診断サーバ diagnose にコピーするスクリプトの例を次に示します。
cp *.rec var/mfcobol/es/diagnose cp console.log /var/mfcobol/diagnose/es/console.aux cp console.bak /var/mfcobol/diagnose/es/console.bak
必要なデータを診断サーバにコピーした後、問題が発生したサーバを再起動します。
コンソールログを表示するための他のオプションがあります。これは、上記のコマンドを使用して問題が発生したサーバからコピーした診断ファイルが保存されている診断サーバでのみ意味のあるオプションです。これらのオプションは次のように使用します。
システムトレースの表示は、ヘルプトピックの『システムトレースの表示』を参照してください。ただし、オプションが複雑なため詳しくは例を参照してください。
システムトレーステーブルのトレースを取得するには、メニューの「診断」グループで「トレース」と「A」または「B」のどちらかをクリックして A データセットか B データセットを選択します (メモリ内トレーステーブルが診断サーバに属するため、「C」は選択しないでください)。次に、1 つのトレースインデックスエントリにまとめるトレースブロックの数を「ブロック数」に指定します。[表示] をクリックします。図 11-2 に、「トレースインデックス」ページを示します。
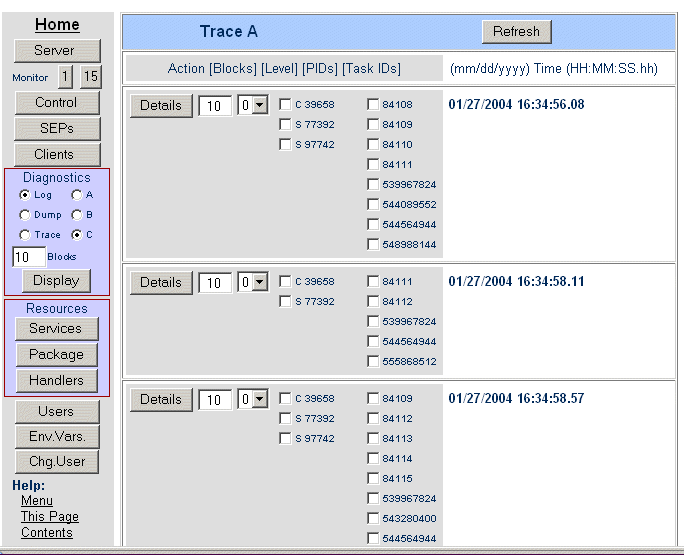
図 11-2: 「トレースインデックス」ページ
ブロックのサイズはシステムトレーステーブルのサイズと同じです。つまり、各ブロックには、サーバの「サーバの編集」ページの「トレーステーブルのサイズ」で指定した数のトレースエントリが含まれます。各インデックスエントリにはタイムスタンプ情報も表示されます。これは、各ブロックの最初のトレースエントリのタイムスタンプです。これらのタイムスタンプは、特定のイベントへと検索範囲を狭めていくのに役立ちます。
実際のトレースを表示するには、該当のインデックスエントリに移動し、各フィールドの値を次のように選択します。
| 0 | サービスの開始、モジュールの開始、モジュールの終了、およびサービスの終了これは、デフォルト設定です。 |
| 1 | エンタープライズサーバ API の入口と出口点 |
| 2 | サブシステムのトレースエントリ |
| 3 | フォーマットしたデータを提供できるすべてのエントリ |
| 4 | すべてのトレースエントリ |
| C | 通信プロセス (MFCS) |
| F | Fileshare サーバ (内部) |
| J | ジャーナルコントロール |
| M | サーバマネージャ |
| R | 復元 |
| S | サービス実行プロセス (service execution process; SEP) |
| U | 不明 |
| Z | 汎用端末またはクライアント |
「レベル」、「PID」、および「タスク ID」コントロールは、特定の情報のみを選択できるフィルタの役割をします。「レベル」をデフォルトの 0 にし、「PID」または「タスク ID」のチェックボックスをチェックしない場合は、当該トレースインデックスエントリが表すブロックにエントリをもつすべてのプロセスおよびタスクの、最小レベルの情報が表示されます。トレース情報を生成しないように選択することもできます。プロセスとタスクの両方を選択し、選択したプロセスで、選択したどのタスクも実行されない場合には、トレース情報は生成されません。1 つのタスクは、複数のプロセスで実行されることはありません。タスクに通信処理が含まれる場合は、この処理は送信側受信側それぞれのプロセスとタスクで実行され、2 つのタスク ID を自動的に関連付ける方法はありません。表示されるのは、フィルタリングに関係なく常にブロックの最初のトレースエントリです。
ここでは、これらのコントロールを使用して表示する情報を選択する方法の例を示します。メニューの「診断」グループの「ブロック数」で 10 を指定します。データセット内に情報のブロックが実際に 60 ブロックあるため、6 個のインデックスエントリが表示されます。3 番目と 4 番目のインデックスエントリに表示された特定の SEP を対象にします。3 番目のインデックスエントリの「ブロック数」に 20 を指定し、対象の SEP のプロセス ID の隣にあるチェックボックスを選択して [詳細] をクリックします。これにより、3 番目のインデックスエントリの最初のブロックから始まる、対象の SEP を含むすべてのブロックのその SEP のトレースエントリのみが表示されます。
各トレースエントリに含まれる情報は次のとおりです。
| Heading | 目次 |
| None | トレースされたイベントの説明 (説明がある場合) |
| Seq | エントリの連続番号 (昇順) |
| Task-Nbr | 5 桁のタスク番号 |
| ProcessID | 5 桁のプロセス ID |
| ID | トレースされたイベント、コマンド、命令の ID。 この ID は 4 バイトの 16 進数です。 |
| hhmmsshh | トレースエントリが書き込まれた時刻を示すタイムスタンプ。 タイムスタンプの形式は、時、分、秒、および 1/100 秒です。 |
| aaaa bbbb | 8 バイトのエントリ固有データ |
トレースの表示の終了後、[戻る] をクリックして「トレースインデックス」ページに戻ります。
ダンプの表示は、ヘルプトピックの『ダンプの表示』を参照してください。ただし、トレースの表示と同様に、オプションが複雑なため詳しくは例を参照してください。
要約ダンプまたは詳細ダンプのどちらでも表示できます。要約情報は詳細ダンプの最後に含まれます。要約ダンプと詳細ダンプのどちらにも、システムトレースとローカルトレース (SEP のトレース) が含まれます。
ダンプを表示するには、メニューの「診断」グループで「ダンプ」と「A」または「B」をクリックして A データセットか B データセットを選択します。または、「C」をクリックしてダンプ X データセット (外部的にトリガーされたダンプで作成されたデータセット) を選択します。出力結果には影響しないので「ブロック数」は無視してください。[表示] をクリックします。図 11-3 に、「ダンプインデックス」ページを示します。
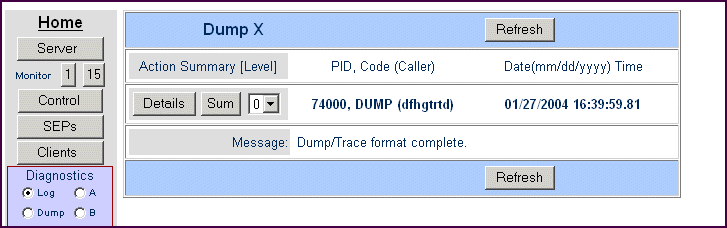
図 11-3: 「ダンプインデックス」ページ
インデックスエントリには次の情報も表示されます。
ダンプを表示するには、該当のインデックスエントリに移動し、「レベル」(左から 3 番目のコントロール) でフォーマットしたダンプに表示するトレースの詳細レベルを指定します。次のオプションがあります。
| 0 | サービスの開始、モジュールの開始、モジュールの終了、およびサービスの終了 |
| 1 | エンタープライズサーバ API の入口と出口点 |
| 2 | サブシステムのトレースエントリ |
| 3 | フォーマットしたデータを提供できるすべてのエントリ |
| 4 | すべてのトレースエントリ。 これは、デフォルト設定です。 |
ローカルトレーステーブル (SEP のトレース) のレベルは 0 または 1 のどちらかです。
このオプションの選択により、詳細ダンプの出力結果は異なりますが、要約ダンプの出力は変わりません。
完全なダンプ情報を表示する場合は [詳細] をクリックし、要約ダンプを表示する場合は [要約] をクリックします。
ダンプの表示の終了後、[戻る] をクリックして「ダンプインデックス」ページに戻ります。
エンタープライズサーバの起動時に、コンソールログに次のような INVALID_CREDENTIALS エラーが表示されることがあります。
CASCD4002W Error (INVALID_CREDENTIALS) binding to MFDS (CASCD4002W MFDS へのバインディング処理中にエラー (INVALID_CREDENTIALS) が発生しました。) CASCD0102F TX Daemon Failed to Initialize (CASCD0102F TX デーモンが初期化に失敗しました。)
これは、Directory Server のユーザ ID とパスワード (暗号化形式の) の詳細情報を保持している内部ファイルに問題があることを示します。このエラーが表示された場合は、次のことを確認してください。
UNIX システムは、システム上の各プロセスが使用できるさまざまなシステムリソースを制限します。この制限により、プロセスがすべてのシステムリソースを不当に使用してマシンを専有して他のプロセスが実行できなくなることを防ぎます。場合によっては、Enterprise Server の運用環境を、デフォルトのリソース制限を超えてリソースを使用できるように構成する必要があります。
制限されるリソースの種類、そのリソースのデフォルトの制限値、およびオペレーティングシステムでサポートする値の上限は、UNIX のバージョンとシステムでリソースの制限がどのように構成されているかによって異なります。詳細は、使用しているオペレーティングシステムのマニュアルを参照してください。一般に UNIX システムでは、各プロセスが使用するメモリサイズ、CPU 時間、およびオープンファイルの数 (ネットワークソケットの数も含む) と、各プロセスが作成するファイルのサイズが制限されます。
エンタープライズサーバが大量のクライアント負荷を処理する必要がある場合、リソースが足りない状態で動作することになります。リソースの制約の影響を最も受ける Enterprise Server の構成要素は、Micro Focus の通信プロセスである mfcs32 です。エンタープライズサーバを起動するたび、mfcs32 プロセスが 1 つ起動されます。
mfcs32 プロセスがメモリまたはスタックのリソース制限に達すると、通常は、さらに会話を処理するためにスレッドを新たに作成できません (既存の会話のどれかが終了しない限り)。また、HTTP ヘッダーを解析するなどのタスクに対してもメモリを割り当てることができない場合があります。この状態で、通信コンソールログ (log.html) に書き込まれる一般的なメッセージを次に示します。
mfcs32 プロセスがファイル記述子の制限に達すると、新しい会話用のソケットを作成できません。この場合には、エラーはログに書き込まれませんが、会話はすぐに終了し、クライアントによってエラーが報告されます。
エンタープライズサーバが長時間実行される場合は、エンタープライズサーバの 1 つ以上のプロセスが CPU 時間の制限に達することがあります。この場合には、問題のプロセスはオペレーティングシステムによって強制終了されます。通常は、Enterprise Server はこの状態を検出して強制終了されたプロセスを再起動します。ただし、問題のプロセスが実行していた処理 (サービス実行プロセスの場合はサービスの実行、通信プロセスの場合はクライアントとの会話) は失われます。Enterprise Server のコンソールログ (console.log ファイル) にエラーメッセージが記録されますが、プロセスが強制終了されて再起動されたことは言及されません。
システム全体でのリソース制限のデフォルト値または最大値は、UNIX プラットフォームとその構成によって異なります。詳細は、使用しているオペレーティングシステムのマニュアルを参照してください。
リソース制限は、個々のプロセスおよびそのプロセスが起動するプロセスに対して設定できます。たとえば、Enterprise Server の Administration Console からエンタープライズサーバを起動する場合は、Directory Server のプロセス mfds32 (Administration Web インターフェイスを提供する) からリソース制限を継承します。Directory Server を起動する際に加えたリソース制限への変更は、Web インターフェイスを使用して起動されたエンタープライズサーバのプロセスにも反映されます。一方、コマンド行で casstart コマンドを入力してエンタープライズサーバを起動する場合は、casstart コマンドを実行する前に現在のシェルに対してリソース制限を設定することができ、これにより、そのエンタープライズサーバのリソースを制御できます。
UNIX の ulimit ユーティリティを使用して現在のシェルに設定されているリソース制限を確認または変更できます。ulimit コマンドの正確な構文と出力は、UNIX バージョンによって異なります。詳細は、ご使用のマニュアルを参照してください。一般に、ulimit -a を使用すると、次のように現在設定されているリソース制限がすべて表示されます。
$ ulimit -a time(seconds) unlimited file(blocks) 2097151 data(kbytes) 131072 stack(kbytes) 32768 memory(kbytes) 32768 coredump(blocks) 2097151 nofiles(descriptors) 2000
これは AIX 5.2 システムの場合の出力です。この出力から、このシェルから起動されたプロセスには CPU 時間の制限がないこと、通常ファイルとコアダンプファイルのサイズが 2097151 ブロック (1 ブロックは 512 バイトで、合計 1 GB) に制限されていることがわかります。データ、スタック、およびメモリサイズの制限はすべて、プロセスが使用できるメモリのサイズの制限です。エンタープライズサーバの場合には、スタックの設定は mfcs32 プロセスが会話処理のために作成できる最大スレッド数を制限します。データの設定は、mfcs32 プロセスが会話処理のために割り当てることができる仮想メモリのサイズを制限します。メモリの設定は、プロセスが使用できる物理メモリ (RAM) のサイズを制限し、通常、エンタープライズサーバにはそれほど重要ではありません。最後の制限はファイル記述子の数です。mfcs32 では、ログファイル用などのさまざまな目的で数個と、リスナーについて 1 つのファイル記述子が必要です。残りの記述子は、クライアントとの個別の会話用です。この例では、mfcs32 が同時にクライアントに接続できる数は 2000 より低い数値に制限されています。
ulimit コマンドで設定するリソース制限には、ハード制限とソフト制限の 2 種類があります。デフォルトでは、ulimit コマンドで表示および設定するのはソフト制限です。ソフト制限は、実際にプロセスに影響する制限です。ハード制限はソフト制限の最大値です。ユーザまたはプロセスは、ソフト制限をハード制限の値まで引き上げることができます。スーパーユーザ権限をもつプロセスのみがハード制限の値を引き上げることができます。
たとえば、Enterprise Server のリソース制限に達しつつある場合に、スタック制限の値を引き上げることで問題が解決するかを確認するには、次の操作を行います。
$ ulimit -s 32768
$ ulimit -H -s 4194304
$ ulimit -s 65536
$ casstart
手順 4 では、コマンド行からエンタープライズサーバを起動しています。Administration Web インターフェイスからエンタープライズサーバを起動したい場合は、ソフト制限の値を引き上げた後にそのシェルのコマンド行から Directory Server を起動して、そこからエンタープライズサーバを起動する必要があります。
Copyright © 2006 Micro Focus (IP) Ltd. All rights reserved.