

|
COBOL言語の概要 | 翻訳集団の概念 | |
この章では、COBOL言語の概念を説明する。
COBOL言語の最も基本的でそれ以上分割できない単位は、文字である。COBOLの文字列および分離符として 使用できる文字集合は、英字、数字、特殊文字から構成される。文字集合を構成する文字を以下に示す。
| 文字
|
意味
|
|---|---|
| 0 から 9 | 数字 |
| A から Z | 大文字の英字 |
| a から z | |
| 空白 | |
| + | 正号 |
| - | 負号またはハイフン |
| * | 星印 |
| / | 斜線 |
| = | 等号 |
| \ | 通貨記号 |
| . | 終止符または小数点 |
| , | コンマまたは小数点 |
| ; | セミコロン |
| " | 引用符 |
| ' |
|
| ( | 左かっこ |
| ) | 右かっこ |
| > | より大きい記号 |
| < | より小さい記号 |
| : | |
| & | |
| _ | |
![]() 小文字を文字列や原文語に使用できる。
ただし、文字定数や絵記号として使用した場合は例外である。各小文字は、対応する大文字と等しいものとする。
小文字を文字列や原文語に使用できる。
ただし、文字定数や絵記号として使用した場合は例外である。各小文字は、対応する大文字と等しいものとする。
このCOBOLシステムは、上記の文字集合に制限されている。しかし、文字定数、注記行、注記項、データの内容には、 COBOL 翻訳集団の文字を入れることができる。(付録の文字集合と文字の照合順序 を参照。)
個々の文字をつないで、文字列または分離符とする。分離符には他の分離符または文字列をつなぐことができる。 文字列には分離符だけをつなぐことができる。文字列と分離符をつないでいくことにより、 翻訳集団の本文ができる。
分離符(separator)は、1つ以上の句読文字をつないだものである。分離符の構成に関する規則を、以下に記す。
![]() 左右の引用符において、アポストロフィまたは引用符を引用記号文字として使用できる。
左右の引用符において、アポストロフィまたは引用符を引用記号文字として使用できる。
句読文字の右側の引用符とは、以下のいずれかである。
左側の引用符の直前は、空白、左かっこ、仮原文区切り記号のいずれかとする。右側の引用符の直後は、分離符の空白、コンマ、セミコロン、終止符、右かっこ、右側の仮原文区切り記号のどれかとする。左側の引用符の直前、および右側の引用符の直後のこれらの分離符は、分離符としての引用符の一部を構成するものではない。
![]() 左側の仮原文区切り記号の直前の空白は、省略可能。
左側の仮原文区切り記号の直前の空白は、省略可能。
仮原文区切り記号は一対として、仮原文
![]() および動詞記号
および動詞記号
を囲むときだけ使用する。 (翻訳指示文の原始文操作および Micro Focus COBOL OO言語拡張のメソッドインターフェイス定義の章を参照。)
PICTURE文字列(データ部 - データ記述のPICTURE(形式)句の章を参照。) または数字定数中の句読文字は、PICTURE句の文字列または数字定数を指定するための記号であり、句読文字とはみなされない。PICTURE句の文字列は、分離符の空白、コンマ、セミコロン、終止符によってのみ区切られる。
分離符の構成に関する規則は、文字定数、注記項、注記行の中の文字には適用しない。
文字列(character-string)はひとつながりの文字であって、COBOLの語、定数、PICTURE文字列、注記項を形成する。文字列は分離符で区切る。
![]() COBOLの語(word)は30字以内の文字列であって、翻訳指示語、コンテキストセンシティブ語、利用者語、システム名、予約語、関数名に使用する。特殊文字を含まないCOBOLの語は文字と数字とハイフン
COBOLの語(word)は30字以内の文字列であって、翻訳指示語、コンテキストセンシティブ語、利用者語、システム名、予約語、関数名に使用する。特殊文字を含まないCOBOLの語は文字と数字とハイフン
![]() と下線から構成される。
と下線から構成される。
非特殊文字語においては、ハイフン
![]() または下線
または下線
を先頭または末尾に置いてはならない。小文字は対応する大文字と等しいものとみなされる。. .
![]() 文字列は31文字含むことができる。
文字列は31文字含むことができる。
![]() 原始要素内では、下記の規則が適用される。
原始要素内では、下記の規則が適用される。
利用者語:利用者語(user-defined word)はCOBOLの語であって、句や文の書き方を満足するように利用者が指定するものである。利用者語の各文字は下記の一連の文字の中から選択する。
実際の利用者語には以下の種類がある。
1つの原始要素の中では、利用者語が次に示すように互いに重ならない種類に分かれる
![]() 定数名、
定数名、
データ名、
![]() プロパティ名、
プロパティ名、
レコード名、
![]() 分割キー名、
分割キー名、
![]() 型定義名
型定義名
区分番号およびレベル番号を除く利用者語はすべて、上記の互いに重ならない種類のうちのただ1つに属する。更に、同じ種類の利用者語は、一意参照の節で指定されたものを除き、すべて一意でなければならない。
段落名、節名、レベル番号、区分番号以外の利用者語はすべて、最低限1文字の英字、
![]() またはハイフンを1つ含まなければならない。
またはハイフンを1つ含まなければならない。
区分番号およびレベル番号は一意である必要はない。区分番号およびレベル番号は他の区分番号やレベル番号と同じであってもよいし、段落名や節名とも同じであってもよい。
下記の利用者語は操作環境に対して外部化される。
![]() クラス名、
クラス名、
![]() 関数プロトタイプ名、
関数プロトタイプ名、
![]() インターフェイス名、
インターフェイス名、
![]() メソッド名、
メソッド名、
![]() プログラムプロトタイプ名、
プログラムプロトタイプ名、
![]() 利用者関数名
利用者関数名
これらの名前のいずれかの代わりに、またはそれに加えて、定数を指定した場合、その定数の内容が操作環境に対する外部名となる。そのさい、大文字と小文字は区別される。定数を指定しなかった場合は、小文字を大文字に変換して外部名が作成される。コンパイラ指令のFOLD-CALL-NAMEを使用すると、外部名化したクラス名、インターフェイス名、プログラム名を大文字にするか小文字にするかを制御できる。コンパイラ指令のOOCTRLを使用すると、外部名化したメソッド名を大文字にするか小文字にするかを制御できる。+Fと-Uを指定すると、メソッド名は小文字にされるこれが省略時の解釈である。
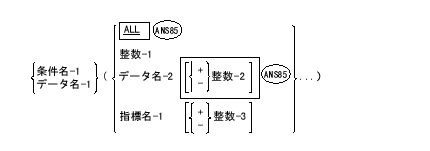
| 条件名: | 条件名(condition-name)とは、データ項目がとるすべての値の組の中の、特定の値または値の組または値の範囲に付けた名前である。条件名を付けたデータ項目を条件変数(conditional
variable)という。条件名は、データ部または環境部の特殊名段落の中で定義できる。特殊名段落では、実行時スイッチのオンの状態、オフの状態、または両方の状態に命名する。
条件名を使用するのは、次の場合だけである。
|
| |
定数名(constant-name)とは固定的な値に付けた名前である。 |
| 呼び名: | 呼び名(mnemonic-name)は、作成者語(implementor-name)に利用者語を割り当てるものである。この指定は環境部の特殊名段落の中で行う。(環境部の章の特殊名段落の節を参照。) |
| 段落名: | 段落名(paragraph-name)とは、手続き部の段落に付けた名前である。段落名が等しいと判断されるのは、同じ数の数字または文字が同じ順序で並んでいる場合だけである。 |
| 節名: | 節名(section-name)とは、手続き部の節に付けた名前である。節名が等しいと判断されるのは、同じ数の数字または文字が同じ順序で並んでいる場合だけである。 |
| その他の利用者語 | その他の利用者語の定義については、用語集を参照。 |
システム名: システム名(system-name)とは、操作環境との連絡に使用するCOBOLの語である。
システム名には、最低1つの英字を入れるか、
![]() または1つのハイフンを入れる。
または1つのハイフンを入れる。
システム名には、以下の3種類がある。
1つの処理系の中では、システム名のそれぞれの種類は互いに重なり合わない。1つのシステム名はただ1つの種類に属する。
上記のシステム名は、それぞれ用語集に定義を記載してある。
![]() 関数名: 関数名(function-name)は、COBOL原始
要素の中で使用できる語のリストの1つである。
関数名と同じ語を利用者語またはシステム名として、原始要素中の別々の文脈において使用できる。ただし、LENGTHとRANDOMとSUMは例外で、利用者語またはシステム名としては使用できない。
(手続き部 - 組み込み関数の章の関数の定義の節を参照。)
関数名: 関数名(function-name)は、COBOL原始
要素の中で使用できる語のリストの1つである。
関数名と同じ語を利用者語またはシステム名として、原始要素中の別々の文脈において使用できる。ただし、LENGTHとRANDOMとSUMは例外で、利用者語またはシステム名としては使用できない。
(手続き部 - 組み込み関数の章の関数の定義の節を参照。)
予約語: 予約語(reserved word)とは、COBOL翻訳集団の中で用いる語のうちの、予め予約されていて、利用者語またはシステム名としては翻訳集団中で使用できないものである。予約後は、一般形式での指定に従ってのみ使用される (付録の予約語を参照。)
予約語には、下記の種類がある。
| 必要語: | 必要語(key word)とは、 翻訳集団の中である書き方をするときに、必ず書かなければならない語である。それぞれの一般形式の中で、必要語は大文字で記し下線を引いてある。
必要語には、下記の3種類がある。
|
| 補助語: | 補助語(optional word)とは、それぞれの一般形式の中で、大文字で記してあるが下線を引いてない語である。補助語は書いても書かなくてもよい。補助語を書いたか書かなかったかによって、COBOL 原始要素の意味が変わることはない。 |
| 特殊レジスタ: | 特殊レジスタ(special register)とは、COBOLの特殊な機能に関連する情報を記憶しておくために、COBOLコンパイラによって作成される記憶領域である。特殊レジスタには名前を付け、その名前によって参照する。これらについては、この節の特殊レジスタの項で後述する。 |
| 表意定数: | 表意定数(figurative constant)とは、特殊な定数値に予め付けた名前である。この名前によって、値を参照する。具体的な表意定数については、この節の表意定数の値の項で後述する。 |
| 特殊文字語: | 特殊文字語(special-character word)とは、特殊な文字の予約語である。 |
| 定義済みオブジェクト一意名: | あらかじめ定義されたオブジェクト一意名などの予約語である。以下のものがある。
|
![]() 文脈依存語:
文脈依存語は、一般形式に指定されているようにだけ予約されるCOBOLの語である。同じ語を、関数名、利用者語、システム名として使用できる。文脈依存語および予約された文脈については、付録の文脈依存語を参照。
文脈依存語:
文脈依存語は、一般形式に指定されているようにだけ予約されるCOBOLの語である。同じ語を、関数名、利用者語、システム名として使用できる。文脈依存語および予約された文脈については、付録の文脈依存語を参照。
![]()
ある原始要素の中に別の原始要素が、直接的または間接的に、含まれることがある。各原始要素は、他の原始要素によってまったく同じに名前を付けられた利用者語を使用することができる。 (COBOLの語の節の利用者語の解説を参照。) このような場合、ある原始要素で参照した名前は、違う種類の利用者語であってもその原始要素に記述されているものを指すのであって、他の原始要素中に記述されている同じ名前のものを指すのではない。
利用者語のうちの下記の種類に属するものは、利用者語を宣言した原始要素中の文または記述項においてだけ、参照できる。
利用者語のうちの下記の種類に属するものは、どのCOBOL原始要素からも参照できる。
利用者語のうちの下記の種類に属するものは、それらが構成節の中に宣言されている場合、その構成節を含む原始要素またはその原始要素に含まれる原始要素中の文または記述項からだけ、参照できる。
上記の条件に該当しない場合、利用者語のうちの下記の種類に属するものには、宣言および参照に関して、特別の表記法が適用される。
![]()
プログラムのプログラム名は、プログラムの見出し部のプログラム名段落で宣言される。プログラム名を参照できるのは、CALL(呼ぶ)文、
![]() CHAIN文、
CHAIN文、
CANCEL 文、
![]() SET文、および
SET文、および
プログラム終了見出しから1つの実行単位を構成するいくつかのプログラムに付けられたプログラム名は、必ずしも一意であるとは限らない。しかし、1つの実行単位中の2つのプログラム名が同じである場合、少なくとも一方のプログラムは、もう一方のプログラムを含まない別のプログラムの中に直接的または間接的に含まれていなければならない。
プログラム名の適用範囲を規定する規則は、下記のとおり。
![]() または、プログラムに再帰的な属性がある場合は、そのプログラム自体の内部から参照できる。
または、プログラムに再帰的な属性がある場合は、そのプログラム自体の内部から参照できる。
![]() ただし、共通属性をもつプログラムおよびそのプログラムに含まれるプログラムからは、そのプログラムが再帰的な属性を持つ場合を除き、そのプログラム名を参照できない。
ただし、共通属性をもつプログラムおよびそのプログラムに含まれるプログラムからは、そのプログラムが再帰的な属性を持つ場合を除き、そのプログラム名を参照できない。
![]()
原始要素の中に条件名、データ名、ファイル名、レコード名、報告書名、
![]() および型定義名
および型定義名
が宣言されている場合、これらの名前はその原始要素の中でだけ参照できる。ただし、これらの名前のうちのいくつかが大域的に使用され、その原始要素中に他の原始要素が含まれる場合は、含まれる他の原始要素からも参照できる。
単一の原始要素の条件名、データ名、ファイル名、レコード名、報告書名、
![]() および型定義名
および型定義名
に付けた名前の一意性に関する必要条件については、前述COBOLの語の節の利用者語の解説を参照。
ある原始要素の中で、その中に含まれる原始要素中に宣言されている条件名、データ名、ファイル名、レコード名、報告書名、
![]() および型定義名
および型定義名
は参照できない。
大域名は、それが宣言されている原始要素の中、あるいはその原始要素に直接的または間接的に含まれている原始要素の中から参照できる。
原始要素Aに原始要素Bが直接的に含まれている場合、両方の原始要素で条件名、データ名、ファイル名、レコード名、報告書名、
![]() および型定義名
および型定義名
をそれぞれ同じ利用者語を使用して設定できる。両方の原始要素中に存在する名前を原始要素B中で参照した場合、下記の規則に従って、どちらのものを指すかが判定される。
![]()
大域的属性をもつデータ項目が指標名を記述した表を含む場合、その指標名も大域的属性をもつことになる。したがって、指標名の範囲は、その指標名によって名付けられる指標を持つ表に名前を付けるデータ名のものと同じであり、データ名用の名前の範囲規則が適用される。
指標名を修飾することはできない。
![]() 指標名は修飾することができる。
指標名は修飾することができる。
![]()
ソース要素内で参照されるクラスのクラス名は、それを含むクラス定義の名前であるか、またはそのソース要素またはそれを含むソース要素の
![]() またはクラス管理段落
またはクラス管理段落
内に宣言されていなければならない。
該当のクラス名に関して翻訳集団内で定義できるクラス定義は1つだけである。その翻訳集団内に定義がなくともかまわない。
ソース要素内で参照されるインターフェイスのインターフェイス名は、それを含むインターフェイス定義の名前であるか、またはそのソース要素またはそれを含むソース要素のリポジトリ段落内に宣言されていなければならない。
該当のインターフェイス名に関して翻訳集団内で定義できるインターフェイス定義は1つだけである。その翻訳集団内に定義がなくともかまわない。
ソース要素のクラス管理段落またはリポジトリ段落内で宣言されたクラス名またはインターフェイス名は、そのソース要素およびそれにネストされるソース要素の中で使用できる。
![]() ソース要素のクラス管理段落で宣言されたクラス名またはインターフェイス名は、そのソース要素および内包されるソース要素の中で使用できる。
ソース要素のクラス管理段落で宣言されたクラス名またはインターフェイス名は、そのソース要素および内包されるソース要素の中で使用できる。
![]()
メソッドのメソッド名はメソッド名段落中に宣言する。メソッド名を参照できるのは、INVOKE文、メソッド終了見出し、および行中のメソッド呼出しだけである。
クラス定義中に宣言されるメソッドのメソッド名は、そのクラス定義内で一意であるものとする。子クラス内で宣言されるメソッドの名前が親クラスのものと同じであってもかまわない。 ただし、メソッド名段落の条件に従うものとする。
インターフェイス定義中に宣言されるメソッドのメソッド名は、そのインターフェイス定義内で一意であるものとする。継承を受けるインターフェイス内で宣言されるメソッドの名前が継承元のインターフェイスのものと同じであってもかまわない。ただし、メソッド名段落に記述されている条件に従うものとする。
![]()
ソース要素中で参照される関数プロトタイプ名は、それを含む関数定義であるか、または、レポジトリ段落とソース要素のいずれかで宣言されていなければならない。
関数プロトタイプ名がレポジトリ段落で指定され、かつ、その関数プロトタイプ名を宣言する関数プロトタイプが同じ翻訳集団中で指定されている場合は、指定された関数プロトタイプ名が使用され、外部レポジトリ中のこのプロトタイプの情報は無視される。
![]()
ソース要素中で参照されるプログラムプロトタイプ名は、それを含むプログラム定義のプログラム名、またはレポジトリ段落で宣言されたプログラムプロトタイプ名でなければならない。
プログラムプロトタイプがレポジトリ段落で指定され、かつ、同じプログラムプロトタイプ名を宣言するプログラムプロトタイプが同じ翻訳集団中で指定されている場合は、指定されたプログラムプロトタイプが使用され、このプロトタイプの外部レポジトリ中のこのプロトタイプの情報は無視される。
定数(literal)とは、以下のいずれかである。
各定数は、文字定数、数字定数、および各国語型定数のいずれかに属する。
文字定数(nonnumeric literal)とは、計算機の文字集合中で利用できる任意の文字を並べて、両端を引用符
![]() またはアポストロフィ
またはアポストロフィ
で区切ったものである。文字定数の長さは1文字以上160文字以内である。引用符
![]() またはアポストロフィ
またはアポストロフィ
を区切り文字として使用した場合、文字定数内にその区切り文字を含めるには、その文字を2つ並べて書く。 区切り文字ではない文字を文字定数内に含めるには、その文字を1つだけ書く。ランタイム要素中での文字定数の値は文字の列そのものである。ただし、次の条件がある。
その他の句読文字はすべて、分離符ではなく、文字定数の一部を構成する。すべての文字定数の項類(category)は英数字(alphanumeric)である。(データ部 - データ記述の章のPICTURE(形式)句の節を参照。)
![]() さらに、16進数を文字定数として扱うことができる。このためには、X"nn"
という形式で文字定数を書き表わす。ここで、n は0-9とA-Fの16進文字を表わす。nn は160回まで繰り返すことができる。ただし、nの個数は偶数とする。
さらに、16進数を文字定数として扱うことができる。このためには、X"nn"
という形式で文字定数を書き表わす。ここで、n は0-9とA-Fの16進文字を表わす。nn は160回まで繰り返すことができる。ただし、nの個数は偶数とする。
![]() 16進桁の個数は奇数でもよい。
16進桁の個数は奇数でもよい。
数字定数(numeric literal)は、固定小数点数でも浮動小数点数でもよい。
数字定数は、"0"から"9"までの数字と正号、負号、小数点からなる文字列である。この処理系では、数字定数の長さは1文字以上18文字以内である。数字定数を作る際には、下記の規則が適用される。
上記の規則に適合するが、引用符で囲まれている定数は、文字定数として扱われる。
標準データ形式の文字で表した数字定数の大きさは、利用者が指定した数字の桁数に等しいものとする。
![]() さらに、16進数を数字定数として扱うことができる。このためには、
H"
さらに、16進数を数字定数として扱うことができる。このためには、
H"nn" という形式で文字定数を書き表わす。ここで、nは0-9とA-Fの16進文字を表わす。nn
は8回まで繰り返すことができる。ただし、nの個数は偶数とする。
![]()
浮動小数点数定数の書き方は下記のとおり。

仮数部と指数部の符号は、付けても付けなくてもよい。符号を省略すると、正の数として扱われる。
仮数部の長さは、1文字以上16文字以内である。仮数部には小数点を含めなければならない。
指数部は、Eに続けて符号を記した後に、1文字または2文字で指定する。ただし、符号は付けても付けなくてもよい。
浮動小数点定数の値の範囲は、0.54E-78から0.72E+76までである。この範囲から外れる値に対しては診断メッセージが出され、値はそれぞれ0または0.72E+76で置き換えられる。整数の数値定数が必要なときに、浮動小数点数の数値定数を使用しないように、注意すること。
![]()
各国語型定数は、計算機内の保存場所で同一サイズの文字で表示される、一連の各国語文字である。詳しくは、使用しているCOBOLシステムの各国語データ(Unicode)に関する文書を参照。
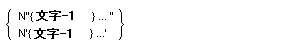
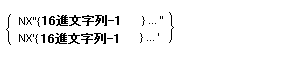
実行時の定数の値は、定数の翻訳時の値の、対応する実行時の値への変換の結果である各国語文字である。
表意定数の値は、COBOLシステムによって作り出される。その値を、下記の予約語を使用して参照する。表意定数として使用するときは、この予約語を引用符で囲んではならない。表意定数の単数形と複数形の値は同じであるので、どちらを使用してもよい。
表意定数の値、およびそれらを参照するために使用する予約語を表 2-1に示す。
| 定数 | 内容 |
|---|---|
| ZERO ZEROS ZEROES |
値"0" を表わす。文脈によっては1つ以上の文字"0" を表わす |
| SPACE SPACES |
計算機の文字集合から1つ以上の空白文字を表わす |
| HIGH-VALUE HIGH-VALUES |
文字の照合順序の最も高い文字を1つ以上表わす(拡張ASCII文字集合ではx"FF") |
| LOW-VALUE LOW-VALUES |
文字の照合順序の最も低い文字を1つ以上表わす(拡張ASCII文字集合ではx"00") |
| QUOTE QUOTES |
1つ以上の文字「" 」を表わす。数値定数をくくるために、原始プログラム中で引用符の代りにQUOTEまたはQOUTESを使用することはできない。したがって、"ABD" を表わすために、QUOTE ABD QUOTEと記すのは誤りである。 |
| ALL literal |
指定された文字が何文字か含まれる文字列を表わす。定数は、文字定数または 表意定数でなければならない。ただし、定数としてALLを指定することはできない。 |
| NULLS |
1つ以上の未設定ポインタ値
を表わす。USAGE POINTER を持つデータ項目、および値がNULLであるポインタ変数はどのデータ項目 も指さないことが保証される。 NULL値は環境間で変化し、通常、各環境用のCOBOL以外の言語で使用される等しい値と一致する。 |
表意定数が何文字かの文字列を表わす場合、その長さは文脈に応じて、COBOLシステムによって決定される。その際、以下の規則が順に適用される。
![]() DISPLAY文の形式
3 における表意定数の使用は、その一般規則で説明する通り、特別な効果を持つ。
DISPLAY文の形式
3 における表意定数の使用は、その一般規則で説明する通り、特別な効果を持つ。
形式に定数が示されているところでは、どこでも表意定数を使用できる。ただし、数字定数に限定されている箇所では、表意定数はZERO(ZEROS, ZEROES)だけを使用できる。
表意定数のHIGH-VALUE(S)またはLOW-VALUE(S)を使用した場合、 , 実際に表意定数が表わす文字は、指定されている文字の照合順序によって決まる。(環境部の章の実行用計算機段落および特殊名段落の節を参照。)
表意定数を表わす予約語は、それぞれが独立した文字列である。ただし、「ALL 定数」は例外で、2つの別々の文字列から構成される。
![]() 表意定数のQUOTE/QUOTESの値は、指令のAPOSTおよびQUOTEの影響を受ける。
表意定数のQUOTE/QUOTESの値は、指令のAPOSTおよびQUOTEの影響を受ける。
![]() 定数の長さが2桁以上ある表意定数の「ALL
定数」を数字項目または数字編集項目に関係付けることは、ANSI '85標準では廃要素に分類される。これはANSI標準の次の全面改訂時に削除される予定である。
定数の長さが2桁以上ある表意定数の「ALL
定数」を数字項目または数字編集項目に関係付けることは、ANSI '85標準では廃要素に分類される。これはANSI標準の次の全面改訂時に削除される予定である。
![]() このCOBOL処理系に組み込まれている方言は、この構文を全面的に使用できる。FLAGSTD指令を使用すると、この構文が使われているすべての箇所を見つけ出すことができる。
このCOBOL処理系に組み込まれている方言は、この構文を全面的に使用できる。FLAGSTD指令を使用すると、この構文が使われているすべての箇所を見つけ出すことができる。
![]() 標準COBOL定義の一環であるにもかかわらず、この構文はX/OpenのCOBOL言語定義からは明示的に除外されている。したがって、X/Openに準拠するCOBOL原始プログラムの中では、この構文を使用すべきではない。
標準COBOL定義の一環であるにもかかわらず、この構文はX/OpenのCOBOL言語定義からは明示的に除外されている。したがって、X/Openに準拠するCOBOL原始プログラムの中では、この構文を使用すべきではない。
![]()
定数名(constant-name)とは、データ部の78レベルのデータ記述項(data description entry)に指定した利用者語である。形式に定数が示されているところでは、どこにでも定数名を使用できる。定数名の働きは、そのデータ記述項に値として指定した定数を書いたのと同じ結果が得られることにある。形式に整数の定数が示されているところでは、整数の値をもつ定数名を使用することができる。例としては、レベル番号、区分番号、PICTURE文字列が挙げられる。
定数名は、定義した後でだけ使用できる。定数名は前方参照の対象とはならない。
![]()
連結式は、連結演算子で分離された2個の作用対象から成る。

特殊レジスタ(special register)は、COBOLシステムによって作成されるデータ項目または一時的な値である。特殊レジスタを参照するには、対応する名前または式を使用する(表 2-2参照)。 その際、以下に示す特別な規則が適用される。また、特殊レジスタには暗黙のデータ記述(PICTURE)が想定される。
| 特殊レジスタ名または式 | 暗黙のデータ記述PICTURE | 使用法 |
|---|---|---|
| |
USAGE IS POINTER | データ名-1の番地を示すポインタ値を生成する。この式は、使用する文で一般形式として明示的に指定する。データ名-1は、連絡節で01レベルおよび77レベルのデータ項目として
宣言される。
|
|
|
X(8) | 現在の日付が記録される。(この日付けは、COBOL 実行環境から提供される。) 次の形式をしている。MM/DD/YY MM は月を、 DDは日を、YY は年(1900年からの下2桁)を表わす数字である。CURRENT-DATEはMOVE文の送出し側としてだけ使用できる。 |
| DEBUG-ITEM | 可変長のグループ項目 | デバッギング節が実行された原因となった理由に関する情報を表す。詳しくは、言語リファレンス - 追加トピックのデバッグモジュールの章を参照。 |
|
|
9(9) | データ名-2によって使用される、記憶領域の現在の バイト数を示す値を生成する。この式は、数字データ項目を使用できるところであればどこでも使用できる。ただし、添字付けまたは部分参照は例外とする。 |
| LINAGE-COUNTER | レコード順ファイル記述の中にLINAGE句が存在する場合に生成される。整数1または、LINAGE句のデータ名1が参照するデータ項目と同じサイズの、符号のつかない整数を説明しているとされる。 | |
|
|
S9(4) COMP
|
以下が可能となる。
プログラムの実行を最初に開始するときには、そのプログラムのRETURN-CODEはゼロに設定される。手続き部の文の中で基本データ項目を参照できるところならば、どこでもRETURN-CODEをデータ名として使用できる。 |
|
|
X(1) | 文字の表現形式を2バイト文字から1バイト文字に戻すために使用する。該当する環境において用いる。 |
|
|
X(1) | 文字の表現形式を1バイト文字から2バイト文字に切り替えるために使用する。該当する環境において用いる。 |
|
|
X(8) S9(8) COMP |
これらの特殊レジスタを手続き部の中で参照できる。ただし、その値はゼロ(数字レジスタの場合)または空白(英数字レジスタの場合)である。 |
|
|
S9(4) COMP | SORT手続きを異常終了させるために使用できる。このレジスタに値16を入れると、次のRELEASEまたはRETURNの後でSORT処理は停止される。 |
|
|
9(5) COMP | EXAMINE...TALLYING文によって作成される情報が記録される。手続き部の文の中で基本データ項目を参照できるところならば、どこでもTALLYをデータ名として使用できる。 |
|
|
9(6) DISPLAY | 現在の時刻(24時間制)が記録される。 (この時刻はCOBOL 実行環境から提供される)次の形式をしている。hhmmsshh は時間を、 mmは分を、 ssは秒を表わす数字である。TIME-OF-DAY
は、MOVE文の送出し側としてだけ使用できる。 |
|
|
X(20) |
COBOL 翻訳集団がCOBOLシステムに投入された時刻と日付が記録される。次の形式をしている。 WHEN-COMPILEDはMOVE文の送出し側としてだけ使用できる。 |
|
|
X(20) |
COBOL 翻訳集団がCOBOLシステムに投入された時刻と日付が記録される。次の形式をしている。 WHEN-COMPILEDはMOVE文の送出し側としてだけ使用できる。 |
| S9(9) COMP |
XMLパーサと、XML PARSE文に記述された処理手順との間で状況を伝達するために使用される。XMLパーサは、各イベントのXML-CODEを解析の終了時に設定する。利用者は、通常のイベントの後に、処理手順のXML-CODEを-1にリセットすることができ、これにより、XMLパーサが利用者の操作による例外として終了したことが示される。これは、返されたXML-CODEの値、-1で示されるEXCEPTION XMLイベントとは区別される。 |
|
| X(30) |
XMLパーサからのイベント情報を、XML PARSE文に記述された処理手順に伝達するために使用される。XMLパーサは、制御を処理手順に渡す前に、XML-EVENT特殊レジスタをXMLイベントの名前に設定する。XML-EVENTはデータを受領する項目として使用することはできない。 |
|
|
XML解析中に定義され、USAGE NATIONALである文書片を含む。XML-NTEXTは、含まれているXML文書片のサイズの、初歩的な各国語データ項目である。XML-NTEXTのサイズは、実行時に動的に変化する。 XML PARSE文の演算数が各国語データ項目である場合、ATTRIBUTE-NATIONAL-CHARACTERおよびCONTENT-NATIONAL-CHARACTERイベントに関しては、XMLパーサは、XML-NTEXTをイベントに関連づけられた文書片に設定した後で、制御を処理手順に渡す。 XML-NTEXTが設定されている場合、XML-TEXT特殊レジスタのサイズは0となる。どの時点でも、サイズが0でないのは、XML-NTEXTとXML-TEXT特殊レジスタのいずれかのみである。 XML-NTEXTに含まれる各国語文字の数を決定するには、LENGTH関数を使用すること。 XML-NTEXTは、受領する項目としては使用できない。 |
||
|
クラス文字である文書片を内包するためのXML解析中に定義される。XML-TEXTは、内包されるXML文書片のサイズの、初歩的な文字データ項目である。XML-TEXTのサイズは、実行時に動的に変化する。 XML PARSE文の演算数が文字データ項目である場合、ATTRIBUTE-NATIONAL-CHARACTERおよびCONTENT-NATIONAL-CHARACTERイベントを除き、XMLパーサは、XML-TEXTをイベントに関連づけられた文書片に設定した後で、制御を処理手順に渡す。 XML-TEXTが設定されている場合、XML-NTEXT特殊レジスタのサイズは0となる。どの時点でも、サイズが0でないのは、XML-NTEXTとXML-TEXT特殊レジスタのいずれかのみである。 XML-TEXTに含まれるバイト数を決定するには、LENGTH関数または、XML-TEXT用LENGTH OF特殊レジスタを使用すること。 XML-TEXT は、受領する項目としては使用できない。 |
| 1 | CURRENT-DATE特殊レジスタの内容の形式は、CURRENT-DATE指令の影響を受ける。 |
| 2 | LENGTH OF特殊レジスタは、Micro Focus 方言では英数字定数で続けても構わない。 |
| 3 | RETURN-CODE特殊レジスタのサイズは、XOPEN指令およびRTNCODE-SIZE指令の影響を受ける。 |
| 4 | XML-TEXT および XML-NTEXT の内容は、XML-EVENTの内容により変化する。詳しくは、表 2-3 を参照。 |
| XML-EVENTの内容 | XML-TEXTまたはXML-NTEXTの内容 |
|---|---|
| ATTRIBUTE-CHARACTER | 属性値の中の、定義済みの参照に対応する単一の文字。 |
| ATTRIBUTE-CHARACTERS | 引用符またはアポストロフィに囲まれた値。値に参照が含まれる場合は、属性値に含まれる文字列の一部でもあり得る。 |
| ATTRIBUTE-NAME | 属性名で、=の左にある文字列。 |
| ATTRIBUTE-NATIONAL-CHARACTER | XML PARSE文中の一意名-1で指定されたXML文書の種類にかかわらず、XML-TEXTは空(から)で、XML-NTEXTは、数字参照に対応する単一の各国語文字を含む。 |
| COMMENT | 左側の文字列、"<!--"と右側の文字列、"-->"の間の注釈テキスト。 |
| CONTENT-CHARACTER | 要素内容の中の、定義済みの参照に対応する単一の文字。 |
| CONTENT-CHARACTERS | 開始タグと終了タグの間の要素内容。ここに他の要素への参照が含まれる場合は、要素内容中の文字列の一部でもあり得る。 |
| CONTENT-NATIONAL-CHARACTER | XML PARSE文中の一意名-1で指定されたXML文書の種類にかかわらず、XML-TEXTは空(から)で、XML-NTEXTは、数字参照に対応する単一の各国語文字を含む(1)。 |
| DOCUMENT-TYPE-DECLARATION | 左右の文字列、 "<!DOCTYPE"および">"を含む、文書種別宣言全体。 |
| ENCODING-DECLARATION | 引用符またはアポストロフィに囲まれたXML宣言中の符号化宣言の値。 |
| END-OF-CDATA-SECTION | つねに文字列、"]]>"を含む。 |
| END-OF-DOCUMENT | 空で、サイズは0。 |
| END-OF-ELEMENT | 終了要素タグまたは空要素タグの名。 |
| EXCEPTION | 走査が完了した文書の一部で、例外が検出された場所までの部分(2)。特殊レジスタ、XML-CODEは、例外を示す一意のエラー符号を含む(3)。 |
| PROCESSING-INSTRUCTION-DATA | 右側の文字列、"?>"を除く、処理指示の残りの部分。ただし、直後の空白文字は含まれるが、直前の空白文字は含まれない。 |
| PROCESSING-INSTRUCTION-TARGET | 処理指示の対象の名で、処理指示の左側の文字列、"<?"の直後に置かれる。. |
| STANDALONE-DECLARATION | 引用符またはアポストロフィに囲まれた、XML宣言中の独立した宣言の値。 |
| START-OF-CDATA-SECTION | つねに、文字列、"<![CDATA["を含む。 |
| START-OF-DOCUMENT | 文書全体。 |
| START-OF-ELEMENT | 開始要素タグまたは終了要素タグの名。要素種別としても知られる。 |
| UNKNOWN-REFERENCE-IN-CONTENT | 参照名。ただし、区切り記号、"&"および ";"を除く。 |
| UNKNOWN-REFERENCE-IN-ATTRIBUTE | 参照名。ただし、区切り記号、"&"および ";"を除く。 |
| VERSION-INFORMATION | 引用符またはアポストロフィに囲まれた、XML宣言中の版宣言の値。これはつねに"1.0"。 |
| (1) | 65,535 (NX"FFFF")より大きいスカラ値を持つ各国語文字は、2つの符号化単位(代理組)を使用して表記される。この符号化単位が、XML-NTEXTの内容についての操作により分離されないよう注意する必要がある。2つの符号化単位で1つの図形文字を形成するため、分離すると無効なデータとなる。 |
| (2) | 符号化の競合の例外は、解析が開始される前に報告される。これらの例外がある場合は、XML-TEXTは、サイズが0であるか、文書からの符号化宣言の値のみを含む。 |
| (3) | XML例外符号について詳しくは、IBM Enterprise COBOL Programming Guideを参照。このマニュアルに記載されていない例外には必ず、201という値が返される。 |
定義済みオブジェクト一意名は、以下の通り。
| 定義済みオブジェクト一意名 | 使用方法 |
|---|---|
|
|
現在のメソッドの実行対象となっているオブジェクトを参照する。メソッドの手続き部で使用できる。SELFが使用されているメソッドを呼び出すために使用されたオブジェクトを参照する。メソッド呼出しにSELFを指定すると、該当のオブジェクトに関して宣言されているすべてのメソッドが検索の対象となる。 |
|
|
現在のオブジェクト(SELF)のクラス・オブジェクトであるオブジェクトを参照する。SELF自体がクラス・オブジェクトである場合は、SELFCLASSはシステム・クラスのBEHAVIORとなる。クラス・オブジェクトのBEHAVIORは自己参照を終了させる働きをする。(つまり、SELFがクラスのBEHAVIORであるならば、SELFCLASSもそうである。) |
|
|
現在のメソッドの実行対象となっているオブジェクトを参照する。メソッドの手続き部で使用できる。INVOKE文でメソッドを呼び出すのに使用されたオブジェクトでありうる。SELFが使用されているメソッドを呼び出すために使用されたオブジェクトを参照する。メソッド呼出しにSUPERを指定すると、実行中のメソッドと同じクラス内に定義されているすべてのメソッドが検索の対象外とされる。 |
|
|
空のオブジェクト参照値を参照する。それはオブジェクトを絶対に参照しないことが保証された固有の値である。NULLは暗黙的にクラス・オブジェクトおよび項類オブジェクト参照として記述されており、一般的オブジェクト参照ではない。受取り側の作用対象にNULLを指定してはならない。 |
PICTURE文字列は、記号として使用されるCOBOLの文字集合の中の、ある種の文字を組み合わせたものである。PICTURE文字列の構成および使用上の規則の詳細については、データ部 - データ記述の章のPICTURE(形式)句節を参照。
PICTURE文字列の指定の中に現れる句読文字は、句読文字としては解釈されない。それらはそのPICTURE文字列の指定の中で使われている記号として解釈される。
注記項(comment-entry)は見出し部の記述項であり、計算機の文字集合中の任意の文字の組合せからなる。注記項は注記を書く目的でのみ使用する。1行以上書くことができ、行のA領域で、予約語である部名、節名、段落名のいずれかが出たところ、
![]() または任意の文字が出たところ
または任意の文字が出たところ
で終了される。標識領域にハイフンを書いて注記項を続けることは許されない。
一般形式(general format)とは句や文の要素の並べ方を指す。このマニュアルでは、句または文を定義する記述のすぐ後ろに一般形式を示す。 2通り以上の並べ方がある場合には、一般形式をいくつかに分けて番号を付けて示す。句は一般形式に示された順番どおりに書かなければならない。任意に指定する句でも、指定する場合には所定の位置に書かなければならない。場合によっては、示された以外の順序で句を記してもよいことがある。その場合は、関連する規則にその旨を明記する。適用範囲、必要条件、制限事項は規則の項に説明する。
構文規則(syntax rule)とは、語や要素を並べて句や文などの大きな要素にまとめる際の規則を指す。構文規則によって、個々の語や要素に制限が課される場合もある。
構文規則は文の形式を定義したり、明確に規定するものである。つまり、文の要素を並べる順序や各要素が表現するものに関する制限を規定する。
一般規則(general rule)とは、単一の要素または一連の要素の意味または意味の関連を定義したり明確に規定したりする規則を指す。この一般規則によって、文の意味や、実行または中間コードの生成に文が与える影響が明確にされる。
句や文を構成する要素(element)には、大文字で記した語、小文字で記した語、レベル番号、角かっこ、中かっこ、連結語および特殊文字がある。
データを、できるかぎり機種に依存しないものとするために、データの性質や特性は装置向けの形式ではなく、標準データ形式で記述する。この標準データ形式は一般のデータ処理応用に向いている。10進数は、計算機の基数系にかかわらず、数値を表現するために使用する。COBOL文字集合中のその他の文字は、文字データ項目を表現するために使用する。
レコードは、レベル構造の概念に従って構成される。この概念は、データを参照するためにレコードを細分化する必要があることから生ずる。いったん細分化したものをさらに細分して、もっと細かいデータとして参照できる。
レコードを最も基本的な単位に細分したもの、つまりそれ以上細分できないものを、基本項目(elementary item)という。したがって、レコードは一連の基本項目から構成されるといえる。または、レコード自体が1つの基本項目である場合もある。
一組の基本項目を参照するために、それらをまとめて集団にする。各集団はいくつかの基本項目を並べて名前を付けたものである。さらに、集団をいくつかまとめて集団とすることもできる。したがって、ある基本項目は何階層もの集団に属することがある。
レベル番号(level-number)は、基本項目と集団項目(group item)の構成を表わす。レコードはデータ項目のうちの最も包括的なものであるので、レコードのレベル番号は 01から始まる。レコードに含まれるデータ項目には、01より大きいレベル番号を付ける。ただし、レベル番号は連続している必要はなく、49を超えないものとする。1レコードに含められるレベル数の最大は49である。この規則の例外である特殊なレベル番号として、66, 77,
![]() 78
78
および88がある(下記を参照)。各レベル番号を用いるごとに、それぞれ記述項を書く。
ある集団は、それに続く集団項目か基本項目のレベル番号に、その集団のレベル番号に等しいか、小さいものが出てくるまでのすべてを含む。ある集団項目に直接属する項目はすべてその集団項目のレベル番号よりも大きな同一のレベル番号を使用しなければならない。
![]() この規則は強制されない。
この規則は強制されない。
例:
| 正しい
|
|
|---|---|
01 A.
05 C-1.
10 D PICTURE X.
10 E PICTURE X.
05 C-2.
|
01 A.
05 C-1.
10 D PICTURE X.
10 E PICTURE X.
04 C-2.
|
レベルの概念が当てはまらない記述項が、以下の4種類存在する。
RENAMES句を用いてデータ項目を再編成するための記述項には、特別のレベル番号66を使用する。
他の項目を細分したのではなく、それ自体も細分されない、独立のデータ項目用の記述項には、特別のレベル番号77を使用する。
条件変数の特定の値に関連付ける条件名を指定するための記述項には、特別のレベル番号88を使用する。
![]() 特定の定数の値に関連付ける定数名を指定するための記述項には、特別のレベル番号78を使用する。
特定の定数の値に関連付ける定数名を指定するための記述項には、特別のレベル番号78を使用する。
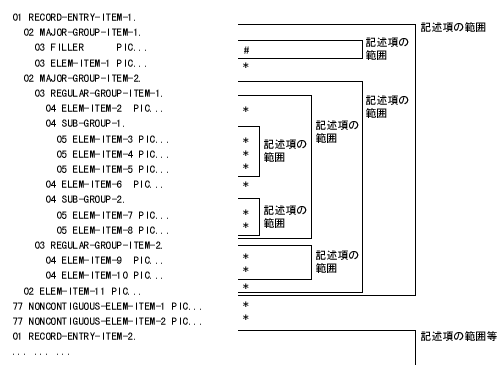
図 2-1: 階層構造をとるレベル番号の例
COBOL原始コードを段落付けで書くのは読みやすくするためであって、文法的に必要なわけではない。
基本項目は、定義上、下位レベルの(レベル番号の大きい)記述項が後ろに続かない項目である。基本項目には、記憶域を定義しなければならない。(データ部 - データ記述の章のPICTURE(形式)句およびUSAGE(用途)句の各節を参照。)
基本項目(上記で"*"を付けたもの)およびFILLER(無名)項目(上記で"#"を付けたもの) だけに記憶域が明示的に取られることに注意すること(これはPICTURE句の働きによる)。集団項目の記憶域は、それに属する下位項目の大きさと桁詰めに必要なバイト数に基づいて、暗黙的に取られる。(データ部 - データ記述の章のSYNCHRONIZED(桁詰め)句節を参照。)
では、分かりやすくするために、レベル番号を連続的に付けた。しかし実際には、レベル番号を連続的に付ける必要はない。したがって、01の次の下位レベルのレベル番号が05、さらにその下位レベルのレベル番号が10といった具合いにしてもよい。
図のデータ・レコード用に取られる記憶域は以下のように構成される。
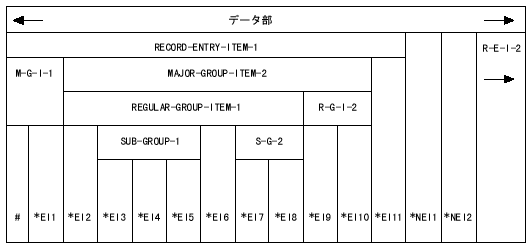
図 2-2: データ・レコード記憶域の割り当て
ここで、
| R-E-I | はレコード・エントリ項目(Record-Entry-Item) |
| M-G-I | は主集団項目(Major-Group-Item) |
| R-G-I | は一般集団項目(Regular-Group-Item) |
| S-G | は従集団(Sub-Group) |
| EI | は基本項目(Elementary-Item) |
| NEI | は独立基本項目(Noncontiguous Elementary-Item) |
基本データ項目、定数、関数は、それぞれ字類と項類を持つ。データ項目の字類と項類は、そのPICTURE文字列か、BLANK WHEN ZERO句か、用途によって定義する。定数の字類と項類については、前述の定数節を参照。
![]() また、組み込み関数の字類と項類は、組み込み関数の定義によって記述する。(手続き部 - 組み込み関数の章を参照。
また、組み込み関数の字類と項類は、組み込み関数の定義によって記述する。(手続き部 - 組み込み関数の章を参照。
集団項目の項類は英数字である。
基本項目の字類と項類の関係を、表にして下に示す。
| 字類 | 項類 |
|---|---|
| 英字 | 英字 |
| 英数字 | 集 英数字 |
| 指標 | 指標 |
| 各国語 | 各国語」 |
| 数字 | 数字 |
| オブジェクト | |
| ポインタ | |
算術符号は、次の2つの項類に分類される。
SIGN(符号)句を使用して、演算符号の位置を明示的に指定できる。この句は指定してもしなくてもよい。演算符号については、後述の文字の表現と基数の選定節を参照。
編集用符号は、PICTURE句の符号編集用文字を用いて、データ項目に挿入する。
基本項目内にデータを収めるときの標準規則は、受取り側データ項目の項類によって決まる。その規則は以下のとおり。
受取り側にJUSTIFIED(桁寄せ)句を指定した場合、データ部 - テータ記述の章のJUSTIFIED(桁寄せ)句節の記述に従って、桁寄せ規則が修正される。
ある種の計算機の記憶装置は、番地付けのための境界(語の境界、半語の境界、バイトの境界)をもつように構成されている。データの格納では、 これらの境界を意識する必要はない。
しかし、データのある種の使い方(算術演算や添字など)では、データが番地付けのための境界に合わせて記憶されている方が効率のよい場合がある。特に、複数個のデータ項目の部分が隣り合う2つの境界の間に含まれていたり、1つのデータ項目が境界によって分断されていたりすると、これらのデータを呼び出したり記憶したりするための、余分な機械命令がランタイム要素の中で必要になる。
余分な機械命令を必要としないように、データ項目を境界に合わせて配置することを、桁詰め(synchronization)という。桁詰めされた項目はその形式に合わせて処理される。桁詰めされた形式への変換は、項目へデータを収める手続き(READとWRITEを除く)を実行するときにだけ行われる。
SYNCHRONIZED句を使用して集団内で特別な桁詰めを行うと、作用対象にその集団を指定している文の実行結果に影響を及ぼすことがある。 暗黙のFILLERの効果、それらの集団を参照する文の意味については、この章で後に詳しく説明する。
数字項目 (PICTUREによって数字と定義されたもの。データ部 - データ記述の章のPICTURE(形式)句節を参照) の値は、記憶装置内では、2進法や10進法などの形式で表現される。どの方式を取るかはUSAGE(用途)句を用いて宣言する(データ部 - データ記述の章のUSAGE(用途)句節を参照。) 指定できる数字の形式は以下の通り。
![]() BINARY,
BINARY,
![]() COMPUTATIONAL-4またはCOMP-4
COMPUTATIONAL-4またはCOMP-4
![]() PACKED-DECIMAL
PACKED-DECIMAL
![]() 英数字関数は常に標準データ形式で表示される。標準データ形式の英数字関数の大きさは、その関数の定義によって定まる。
英数字関数は常に標準データ形式で表示される。標準データ形式の英数字関数の大きさは、その関数の定義によって定まる。
整数関数および数字関数の表現形式は、作成者が下記のように指定する。
整数関数および数字関数は、算術式の中でだけ使用できる。整数関数および数字関数は関数を評価した結果の値を表わすが、その関数の作用対象の構成あるいは受取り側データ項目に制約はない。
ある計算機にデータ表現形式がいくつも備わっているときは、データ記述に指定しないと標準データ形式が使用される。
![]() ただし、整数関数および数字関数は例外とする。
ただし、整数関数および数字関数は例外とする。
数値を表わす0から9のCOBOLの数字は、計算機の記憶域1バイトあたり1文字で、基数10を持つ。 これがCOBOL言語の標準データ形式である。符号付きのデータ項目に符号をSEPARATEと指定しないと、符号は数字の上に付けられる。(データ部 - データ記述の章のSIGN(符号)句節を参照。NUMERIC SIGN句については、環境部の章の特殊名段落節を参照。) SIGN句にLEADINGと指定すれば、符号は左端の数字位置に付けられ、TRAILINGと指定すれば符号は右端の数字位置に付けられる。符号付きデータにどのように符号が組み込まれるかを表 2-4に示す。(数値が負である場合、6番目のビット(値 "40")が0から1に設定される。) 符号付きのデータ項目に符号をSEPARATEと指定すると、数値を表わす数字の他に1文字が符号として付加される。この符号文字は、正か負かに応じて、"+"または "-"となる。符号付きのデータ項目にSIGN句を指定しないと、符号文字は特殊名段落にNUMERIC SIGN句が指定されないかぎり、 右端の数字位置に付けられる。データ記述項にSIGN句を指定すると、NUMERIC SIGN句が指定されていれば、その項目用には無視される。
次の表では、かっこ内の数字はCOBOL文字を示す16進数である。これはシステムによっては、CHARSETコンパイラ指令またはSIGNコンパイラ指令の指定により変わる。
| 符号を付ける前の左端 または右端の値 |
符号付きの値を表わす文字 | |||||
|---|---|---|---|---|---|---|
| 正の値 | 負の値 | |||||
| 文字集合(ASCII) | 文字集合(EBCDIC) | 文字集合(ASCII) | 文字集合(EBCDIC) | |||
| 符号(ASCII) | 符号(EBCDIC) | 符号(EBCDIC) | 符号(ASCII) | 符号(EBCDIC) | 符号(EBCDIC) | |
| 0 1 2 3 4 5 6 7 8 9 |
0(30) 1(31) 2(32) 3(33) 4(34) 5(35) 6(36) 7(37) 8(38) 9(39) |
{(7B) A(41) B(42) C(43) D(44) E(45) F(46) G(47) H(48) I(49) |
{(C0) A(C1) B(C2) C(C3) D(C4) E(C5) F(C6) G(C7) H(C8) I(C9) |
p(70) q(71) r(72) s(73) t(74) u(75) v(76) w(77) x(78) y(79) |
}(7D) J(4A) K(4B) L(4C) M(4D) N(4E) O(4F) P(50) Q(51) R(52) |
}(D0) J(D1) K(D2) L(D3) M(D4) N(D5) O(D6) P(D7) Q(D8) R(D9) |
SIGN句にSEPARATEと指定したときに、DISPLAYデータ項目を記憶するのに必要な文字数は、PICTURE句の中の "9"の数に1を加えた数となる。DISPLAY用と宣言したデータ項目に対しては、SYNCHRONIZED句は効果をもたない。
これらの数字データ項目は、計算機の記憶域では、純粋な2進数の形で保持される。この形式では、数値は2を基数として表わされ、計算機に保持されている各ビットは右端を最下位の桁として位取りされ、各位の2のべき乗値の有無を表わす。 負の数は絶対値の等しい正の数の補数を取り(すべてのビットの値を逆転する)、その結果に1を加えることによって表される。データ項目を記憶するのに必要な文字数は、PICTURE句の中の"9" の数と符号が付けられているかいないか によって決まる。(データ部 - データ記述の章のPICTURE(形式)句、SIGN(符号)句、USAGE(用途)句を参照。) COBOLシステムはCOMPUTATIONALデータ項目に記憶域を割り当てる方法を、バイト記憶方式と語記憶方式の2通り用意している。このCOBOL処理系では特に指定しないと、バイト記憶方式が採られる。
計算機の記憶域の境界:現在の計算機の記憶域の基本的な境界は、通常、8ビットからなる文字を基礎としている。これをバイトという。この基本的な枠組みの中で、計算機はさらに2種類に分類される。1つはバイト以外の境界をもたないものであり、もう1つは複数バイトを単位とする境界をもつものである。ここでは、前者をバイト単位計算機、後者を語単位計算機と呼ぶ。
バイト単位計算機では、COBOLコンパイラは数字データ項目に対して占有するバイト数が最小になるように記憶域を割り当てる。(前述の文字の表現と基数の選定節を参照。) この場合、SYNCHRONIZED句は意味をもたず、効果もない。
語単位計算機の語長には、2バイト、4バイト、8バイトがある。COBOL言語はCOMPUTATIONAL句またはSYNCHRONIZED句が指定されたときに、それに応じてデータ項目に記憶域を割り当て桁詰めできるようになっている。COMPUTATIONAL形式のデータに対する語の割り当て方は、COBOLシステム指令のIBMCOMPを用いて制御する。
| PICTURE句の中の数字(9)の数 | 割り当てられる記憶域のバイト数 | ||
|---|---|---|---|
| 符号付き | 符号なし | バイト単位方式 | 語単位方式 |
| 1-2 3-4 5-6 7-9 10-11 12-14 15-16 17-18 19-21 22-23 24-26 27-28 29-31 32-33 34-35 36-38 |
1-2 3-4 5-7 8-9 10-12 13-14 15-16 17-19 20-21 22-24 25-26 27-28 29-31 23-33 34-36 37-38 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
2 2 4 4 8 8 8 8 16 16 16 16 16 16 16 16 |
桁詰め: データ項目の記述にSYNCHRONIZED句を指定すると、語単位の記憶機能が働いて、そのデータ項目の右端(最下位)が計算機の記憶域の境界に合わせられる。語長に満たない左側の部分は詰めものまたは暗黙のFILLERとして残される。この部分を直接呼び出すことはできないが、集団項目の一部として呼び出すことはできる。
SYNCHRONIZED句を指定された基本データ項目は、必要なバイト数の語(表 2-5を参照)の境界に合わせて配置される。たとえば、語単位の記憶方式では、PICTUREにS9(5)と記述されている数字データ項目は4バイト(データ分3バイトと1バイトの詰めもの)の記憶域を割り当てられる。そして、SYNCHRONIZED句が指定されていれば、次に最も近い4バイトの境界に合わせて(レコードの先頭からこのデータ項目の直前のデータ項目の末尾までの長さが4の倍数であったかのように)配置される。直前の項目の末尾が4バイトの境界に達しない場合は、暗黙のFILLERが補われる。
集団項目中のOCCURS(反復)句(データ部 - データ記述の章のOCCURS(反復)句節を参照)を含むデータ記述にSYNCHRONIZED句を指定した場合には、暗黙のFILLERが補われることがある。これは、最初の要素が計算機の記憶域の境界に合わせて配置されるのと同様に、反復される2番目以降の要素についても境界に位置を合わせるために、余分のバイトが必要になることがあるためである。
暗黙の桁詰め:語単位の記憶方式を採った場合、レコード・レベルのデータ記述はすべて、8バイトの語長の境界に合わせて自動的に桁詰めされる。
例(暗黙のFILLER): 下に示すCOBOLデータ記述によって割り当てられる計算機記憶域を図 2-3に示す。記号の意味は図の下に示してある。
01 UNSYNCHRONIZED-RECORD.
02 UNSYNCHRONIZED-DATA-1 PIC 9(3) DISPLAY.
02 UNSYNCHRONIZED-DATA-2 PIC X(2).
01 COMPOUND-REPEATED-RECORD.
02 ELEMENTARY-ITEM-1 PIC X(2).
02 GROUP-ITEM OCCURS 3 TIMES.
03 ELEMENTARY-ITEM-2 PIC X.
03 ELEMENTARY-ITEM-3 PIC S9(2) COMP SYNC.
03 ELEMENTARY-ITEM-4 PIC S9(4)V9(2) COMP SYNC.
03 ELEMENTARY-ITEM-5 PIC X(5).
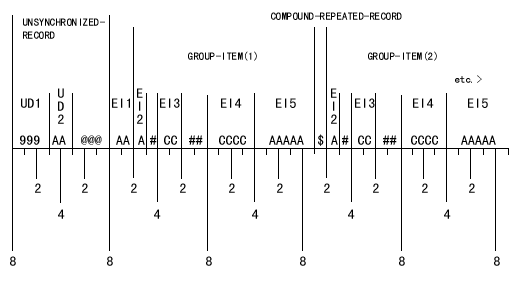
図 2-3: 計算機の記憶域の割当ての例
ここで、
| @ | レコード(01レベル)が自動的に桁詰めされたために割り当てられた、暗黙のFILLERバイトを表わす。 |
| # | 後続のデータ項目が明示的に桁詰めされたために割り当てられた、暗黙のFILLERバイトを表わす。 |
| $ | 集団項目にOCCURS句が指定されたために割り当てられた、暗黙のFILLERバイトを表わす。 |
| 9 | 数字DISPLAY文字用に割り当てられたバイトを表わす。 |
| A | 英数字DISPLAY文字用に割り当てられたバイトを表わす。 |
| C | COMPUTATIONALデータ記憶域用に割り当てられたバイトを表わす。 |
切捨て:前に述べたように、データ項目にUSAGE COMP句を指定すると、データは2進数の形式で保持される。データ項目に割り当てられる記憶域は、PICTURE句に指定した数値に必要な分よりも大きくなることがある。たとえば、PIC 99 COMPと指定したデータ項目には通常、1バイトが割り当てられるが、1バイトは255までの数を保持できる。
ANSI COBOLの規則に準拠するために、数字はその形式にかかわらず、10進数として処理される。算術文が実行された結果、得られた数値が受取り側のデータ項目のPICTUREで可能なよりも大きくなると、桁あふれが発生する。このとき、ON SIZE ERROR(桁あふれ)句が指定してあると、結果は受取り側の項目に入れられない。算術文以外の文では、受取り側の項目の方が大きさが小さい場合、切捨てが発生する。その場合、該当する数値は、受取り側のPICTURE句の指定よりも大きい左側の部分が切捨てられる。
![]() しかし、USAGE COMP句を指定したデータを2進数として処理されるようにできる。この場合、割り当てられた記憶域にデータを収めるために必要があるときにだけ、切捨てが発生する。USAGE
COMP句を指定したデータ項目の処理の仕方は、COBOLシステム指令のTRUNCを用いて制御する。この指令を通じて、PICTURE句の指定に合わせて10進値を切り捨てるか、利用可能な記憶域に合わせて2進値を切り捨てるかを選択できる。その切捨て処理が行われる際、算術文の結果とそれ以外の文による転記とは区別される。
しかし、USAGE COMP句を指定したデータを2進数として処理されるようにできる。この場合、割り当てられた記憶域にデータを収めるために必要があるときにだけ、切捨てが発生する。USAGE
COMP句を指定したデータ項目の処理の仕方は、COBOLシステム指令のTRUNCを用いて制御する。この指令を通じて、PICTURE句の指定に合わせて10進値を切り捨てるか、利用可能な記憶域に合わせて2進値を切り捨てるかを選択できる。その切捨て処理が行われる際、算術文の結果とそれ以外の文による転記とは区別される。
指令にどのような設定がされているかにかかわらず、算術文が実行された結果、得られた数値の10進の桁数が受取り側のデータ項目のPICTUREに指定されているよりも大きくなると、桁あふれが発生する。
![]() 例(切捨て): 操作の中には、TRUNC指令によって結果が変わるものがある。その様子を次に示す。この例では、項目AのPICは99
COMPと記述されている。
例(切捨て): 操作の中には、TRUNC指令によって結果が変わるものがある。その様子を次に示す。この例では、項目AのPICは99
COMPと記述されている。
| 操作 | 結果 | ||
|---|---|---|---|
| TRUNC | NOTRUNC | TRUNC"ANSI" | |
| MOVE 163 TO A | 63 | 163 | 63 |
| MOVE 263 TO A | 63 | 7 | 63 |
| MOVE 13 TO A, ADD 150 TO A |
63 | 163 | 結果は保証されない |
| MOVE 13 TO A, ADD 250 TO A |
63 | 7 | 結果は保証されない |
注:
この形式は、内部浮動小数点データ項目用に使用する。内部浮動小数点データ項目を使用できる場所は、文法的に数字データ項目が使用でき、かつCOBOL言語定義のANSI'74, ANSI'85, ISO2002, OSVS, VSC2 のどれかに構文的に含まれる場所である。内部浮動小数点データ項目は、整数データ項目が必要なところでは使用できない。ただし、特定のCOBOL動詞用の規則に明示的に許されている場合は例外とする。それ以外の構文では、内部浮動小数点データ項目は使用できない。ただし、特別の規則によって許されている場合は例外である。
内部記憶形式はオペレーティングシステムによって異なっていることがある。どのような記憶形式が採られていても、浮動小数点数には4つの要素がある。
![]() USAGE
FLOAT-SHORT は USAGE COMPUTATIONAL-1と同義である。USAGE FLOAT-LONG は USAGE COMPUTATIONAL-2と同義である。
USAGE
FLOAT-SHORT は USAGE COMPUTATIONAL-1と同義である。USAGE FLOAT-LONG は USAGE COMPUTATIONAL-2と同義である。
一般に、USAGE COMPUTATIONAL-1(COMP-1)のデータ項目を単精度浮動小数点数といい、USAGE COMPUTATIONAL-2(COMP-2)のデータ項目を倍精度浮動小数点数という。オペレーティングシステムやCOBOLで利用できる数学登録集によっては、単精度浮動小数点数と倍精度浮動小数点数で制約条件が異なっている場合がある。たとえば、指数部の最大の大きさや仮数部の最大の大きさに制限がある。(詳細については、使用しているオペレーティングシステムまたは数学登録集の浮動小数点数に関する資料を参照。)
ANSI/IEEE 標準 754-1985、倍精度浮動小数点数用IEEE 標準に従うオペレーティングシステムでは、COMPUTATIONAL-1 および COMPUTATIONAL-2 はそれぞれSingle Format および Double Formatと同義である。
内部浮動小数点数表現は、連続した数値を表わすものではないことを理解することが重要である。内部浮動小数点数表現はいろいろなオペレーティングシステムを通じた標準とはなっていない。たとえば、ある内部浮動小数点数表現では、10進数との対応関係は下記のようになっている。
| 内部(16進)表現
|
10進値
|
|---|---|
| x"AD17E148" | -0.12345673E-23 |
| x"AD17E149" | -0.12345810E-23 |
したがって、10進値-.12345678E-23と正確に等しい内部浮動小数点数を求めても、その値は決して得られない。-方、別の内部浮動小数点数表現では、この値は得られるが、上に記した値は得られないということもある。このため、内部浮動小数点数項目と他の数値(外部浮動小数点数項目および浮動小数点数定数を含む)が正確に一致することを求める応用は移植性がなく、同じ入力データを使用しても処理手順の流れを変えなければならないことがある。
内部浮動小数点数項目の記憶域の大きさは、USAGE句によって決まる。USAGE COMPUTATIONAL-1 は項目用に4バイトを予約し、USAGE COMPUTATIONAL-2 は記憶域用に8バイトを予約する。
IBMCOMP指令がオンであると、SYNC句を伴う内部浮動小数点数項目の前に充填文字が埋められることがある。この充填文字はその項目の一部ではなく、その項目に記録されるデータに影響されることはない。
COBOLシステムでは、COMP-1項目は小数点以下7桁、COMP-2項目は小数点以下16桁になっている。しかし、メインフレームとの互換性により、DISPLAY文は、COMP-1には8桁、COMP-2には18桁の小数を表示する。浮動小数点項目を使用するどの操作もこの制限を考慮する必要がある。この制限を超える小数部については無視するようにすること。
![]()
この形式は一般に2進化10進形式という。この形式では、数字データ項目は10を基数として表現される。数値を表わす各数字は1バイトの半分に収められる。その様子を表 2-6に示す。符号は独立の半バイトとして末尾、つまり右端または最下位の位置に付けられる。
![]() 使用されない半バイトがあれば、その値はゼロに設定される。
使用されない半バイトがあれば、その値はゼロに設定される。
| 数字の値 | 16進法による数字の表現 | |
|---|---|---|
| 左の半バイト(偶数桁の数字) | 右の半バイト(奇数桁の数字) | |
| 0 | x"00" | x"00" |
| 1 | x"10" | x"01" |
| 2 | x"20" | x"02" |
| 3 | x"30" | x"03" |
| 4 | x"40" | x"04" |
| 5 | x"50" | x"05" |
| 6 | x"60" | x"06" |
| 7 | x"70" | x"07" |
| 8 | x"80" | x"08" |
| 9 | x"90" | x"09" |
注:偶数桁か奇数桁かは、右側から数える。
shoCOMPUTATIONAL-3用に使用する符号用の桁を表 2-7に示す。この形式に必要な記憶域は、該当データ項目のPICTURE句の中の"9s" の数だけによって決まる。その様子を表 2-8に示す。
| PICTURE句内の符号の表現 | データ項目の値の符号 | 16進法による符号用半バイト |
|---|---|---|
| 符号なし | n/a | x"0F" |
| 符号付き | + | x"0C" |
| 符号付き | - | x"0D" |
| 必要バイト数 | 桁数(符号の有無を問わず) |
|---|---|
| 1 | 1 |
| 2 | 2-3 |
| 3 | 4-5 |
| 4 | 6-7 |
| 5 | 8-9 |
| 6 | 10-11 |
| 7 | 12-13 |
| 8 | 14-15 |
| 9 | 16-17 |
| 10 | 18-19 |
| 11 | 20-21 |
| 12 | 22-23 |
| 13 | 24-25 |
| 14 | 26-27 |
| 15 | 28-29 |
| 16 | 30-31 |
| 17 | 32-33 |
| 18 | 34-35 |
| 19 | 36-37 |
| 20 | 38 |
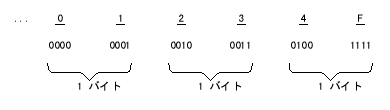
Fは正号を表わす(印刷不能文字)。
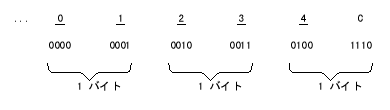
C は正号を表わす。
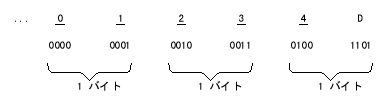
D は負号を表わす。
SYNCHRONIZED句は(LEFTまたはRIGHT句があってもなくても)COMPUTATIONAL-3と宣言されたデータには影響を及ぼさない。
この形式はCOMPUTATIONAL形式と基本的には同じである。詳細については、前述のCOMPUTATIONAL、BINARY、またはCOMPUTATIONAL-4形式節を参照。
ただし、この形式は下記の点がCOMPUTATIONAL形式と異なる。
COMPUTATIONAL-5データ項目を記憶する方式は、オペレーティングシステムによって異なる。オペレーティングシステムの中には、COMPUTATIONAL-5データ項目の最下位のバイトを最下位の番地に収め、以降順次上位のバイトを上位の番地に収めるものがある。たとえば、数字項目を逆の順序で記憶するオペレーティングシステムでは、
h "12 34 56 78 9A"
という内部値を持つ PIC X(5) COMPUTATIONAL-5項目は、
9A 78 56 34 12
というように記憶される。 一方、COMPUTATIONAL-X形のデータ項目(あるいは数字項目の記憶順序を逆転しないオペレーティングシステムのもとのCOMPUTATIONAL-5形のデータ項目)は次のように記憶される。
12 34 56 78 9A
符号なしのCOMPUTATIONAL-5形式のデータ項目に負の値を収めようとする文の働きは、COMP-5コンパイラ指令の影響を受ける。
![]()
ポインタ形式は利用可能なデータ項目のメモリー番地を表す値を保持する。データ項目が利用できなくなった(たとえば、データ項目が含まれているプログラムがキャンセルされた)場合には、ポインタ形式には形式が合致しない値が保持されているとみなされる。
ポインタ形式に割り当てられる省略時の記憶領域の量は操作環境によって異なりうる。しかし、少なくとも4バイトはある。メモリー番地を表現する方法は環境によって異なるが、一般的にはCOBOL以外の言語で使用されている表現と一貫性がある。
システム指令のIBMCOPMを設定した場合、SYNC指定を伴うポインタ・データの前に充てん文字が生成されることがある。それらの文字はデータ項目の一部ではなく、その項目に収められるデータに影響されることはけっしてない。
![]()
手続きポインタ形式は利用可能な手続きのメモリー番地を表す値を保持する。手続きが利用できなくなった(たとえば、手続きが含まれているプログラムがキャンセルされた)場合には、手続きポインタ形式には形式が合致しない値が保持されているとみなされる。
手続きポインタ形式に割り当てられる省略時の記憶領域の量は操作環境によって異なりうる。しかし、少なくとも4バイトはある。COBOL370指令を指定すると、8バイトが割り当てられる。メモリー番地を表現する方法は環境によって異なるが、一般的にはCOBOL以外の言語で使用されている表現と一貫性がある。
システム指令のIBMCOPMを設定した場合、SYNC指定を伴う手続きポインタ・データの前に充てん文字が生成されることがある。それらの文字はデータ項目の一部ではなく、その項目に収められるデータに影響されることはけっしてない。
COBOL原始要素中の要素を定義する、利用者が指定したそれぞれの名前、
![]() およびその原始要素中で参照する名前は、
およびその原始要素中で参照する名前は、
すべて一意とする。 名前は、すべて一意とする。そのためには、同じつづりの名前が他にないか、または名前の階層系列の上位にあるいくつかの名前を付け加えて一意にすることができなければならない。このとき、上位の名前を修飾語(qualifier)といい、一意にする手順を修飾(qualification)という。 名前を一意にするには、必要な修飾語を付け加えればよく、上位の名前をすべて書く必要はない。
データ部では、修飾に用いるデータ名はすべて、レベル指示語(level indicator)またはレベル番号(level-number)の後ろに書いた名前とする。したがって、修飾によって一意にできる場合、
![]() またはそれらがまったく参照されない場合
またはそれらがまったく参照されない場合
を除いて、2つの同じデータ名が同じ集団項目に属する記述項として現れてはならない。 手続き部では、2つの同じ段落名が同じ節にあってはならない。
修飾の階層系列では、レベル指示語の後ろに書いた名前を最高位とし、次にレベル番号01に書いた名前、それに続いてレベル番号02以降49の後ろに書いた名前の順とする。段落名については、節名だけを最高位の修飾語として用いることができる。したがって、階層系列の最高位の名前は、一意でなければならず、修飾することはできない。添字または指標の付いたデータ名や条件変数も、修飾によって一意にすることができる。条件変数の名前は、その条件名の修飾に使用できる。修飾の有無にかかわらず、同じつづりの名前をデータ名と手続き名の両方に使用してはならない。
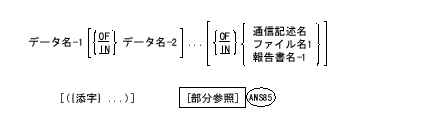
修飾を行うには、データ名または条件名、段落名、原文名の後ろにINまたはOFに続けて修飾語を書く。修飾語をさらに修飾することもできる。INとOFは、論理的には同義語である。
![]() 関数を指定する場合関数定義に従って、その関数を参照する記述の中に、いくつかのパラメータに対する値または値の組を指定する必要がある。そのパラメータの値を用いて、参照した関数の値が算出される。パラメータに実際の値を指定することを引数を与えるという。詳細については、この節の関数一意名節で解説する。
関数を指定する場合関数定義に従って、その関数を参照する記述の中に、いくつかのパラメータに対する値または値の組を指定する必要がある。そのパラメータの値を用いて、参照した関数の値が算出される。パラメータに実際の値を指定することを引数を与えるという。詳細については、この節の関数一意名節で解説する。
修飾の一般書式は、以下の通り。

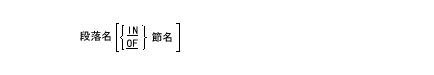


修飾の規則は、以下の通り。
![]() 原始単位の中で明示的に参照される場合、同じ階層系列中の2つのレベルに同じ名前があってはならない。
原始単位の中で明示的に参照される場合、同じ階層系列中の2つのレベルに同じ名前があってはならない。
![]() 段落名も節名も明示的に参照されないかぎり、一意であるかまたは一意にする必要はない。
段落名も節名も明示的に参照されないかぎり、一意であるかまたは一意にする必要はない。
データ名に付けることのできる修飾語の数は、5つまでである。
![]() 50個までの修飾語を付けることができる。
50個までの修飾語を付けることができる。
![]() この規則は強制しない。
この規則は強制しない。
添字(subscript)は、個別にデータ名を付けていない同種の要素のリストまたは表の中の、個々の要素を参照するために使用する。(データ部 - データ記述の章のOCCURS(反復)句節を参照。)
添字として使用できるものは、整数である数字定数、データ名、データ名の後ろに"+" または "-" の演算子を付け、さらに符号なしの整数数字定数を続けたものがある。データ名を使用する場合、このデータは数字基本項目で整数とする。添字全体は、左かっこと右かっこが対になった分離符で区切る。
添字に使用するデータ名には、符号が付いていてもよい。この場合、正でなければならない。添字の最小値は1である。この値は表の最初の要素を指す。表の要素の2番目以降を指す添字の値は、2、3、...という具合になる。添字が取る最大値は、OCCURS句で指定した項目の反復回数の最大値である。
表の要素を一意に識別する添字または添字の組は、対象とする表要素のデータ名の後ろに、一対の左かっこと右かっこで囲んで付ける。表要素のデータ名に添字を付けたものを、添字付きデータ名または一意名という。複数個の添字を指定するときは、データ構造の階層の上位のものから書く。添字は3つまで指定できる。
![]() 添字は7つまで指定できる。
添字は7つまで指定できる。
![]() 添字は16個まで指定できる。
添字は16個まで指定できる。
![]() 代わりに、他の表を記述する指標を使用してもよい。ただし、2つの表に含まれる要素の数が同じであることが条件である。
代わりに、他の表を記述する指標を使用してもよい。ただし、2つの表に含まれる要素の数が同じであることが条件である。
![]() 同じ一意名の中で、添字と指標を混在させることができる。
同じ一意名の中で、添字と指標を混在させることができる。
![]() NOBOUND指令を指定した場合は、この一般規則は実行時に適用されない。
NOBOUND指令を指定した場合は、この一般規則は実行時に適用されない。
![]() 添字が浮動小数点項目の場合、その値は最も近い整数に丸められるか、または、端数が切り捨てられる。
添字が浮動小数点項目の場合、その値は最も近い整数に丸められるか、または、端数が切り捨てられる。
![]() 整数-2または
整数-2または
整数-3を指定した場合、添字の値は次のようにして決定される。演算子に"+" を指定した場合は、
![]() 整数-2または
整数-2または
整数-3の値が追加される。演算子に"-" を指定した場合は、
![]() 整数-2または
整数-2または
整数-3の値が差し引かれる。
これらは、指標名-1を用いて指定した値を用いて指定した値に対して行われる。
![]() または、データ名-2を用いて指定した値に対して行われる場合もあり得る。
または、データ名-2を用いて指定した値に対して行われる場合もあり得る。
指標付け(indexing)を指定して、同種の要素からなる表の中の個々の要素を参照できる。指標(index)を付けるには、表を定義する際に、該当するレベルにINDEXED BY(指標付き)句を指定する。INDEXED BY句を用いて付けた名前を指標名(index-name)といい、付けた指標を参照するために使用できる。指標の値は、対応する表または別の表の中の要素の出現番号を表わす。指標名は、表の参照に使用する前に初期化しておく。指標名に初期値を与えるには、SET(設定)文を指定する。
添字は単なる数字データ項目または定数である。これに対し指標は、表中要素の出現番号を表わす特別な型の項目である。その表現形式は何通りかある。指標の内容は数値とはみなされない。
直接指標付け(direct indexing)は、添字と同じ形式で指標名を使用する方法である。相対指標付け(relative indexing)は、指標名の後ろに演算子"+" または "-" と符号の付かない整数を書き、その全体を一対の左かっこと右かっこで囲んで、表要素のデータ名の後ろに続けた形式で指標名を使用する方法である。相対指標付けによる出現番号は次のようにして決定される。演算子に"+" を指定した場合は、指標の値によって表される出現番号に定数の値が追加される。演算子に"-" を指定した場合は、指標の値によって表される出現番号から定数の値が差し引かれる。複数個の指標を用いるときは、データ構造の階層の上位のものから順に書く。
INDEXED BY句を指定することによってだけ、表に指標を付けることができる。
![]() Aある表用に指定した指標を、他の表に適用できる。ただし、どちらの表も要素の数が同じであることが条件である。
Aある表用に指定した指標を、他の表に適用できる。ただし、どちらの表も要素の数が同じであることが条件である。
指標付きの表の要素を参照する文を実行するとき、その表要素の指標名で参照される指標の値は、1から表要素の反復回数の最大値の範囲を外れてはならない。この制限は、相対指標付けの結果として得られる値にも当てはまる。
![]() NOBOUND指令を指定した場合は、この一般規則は実行時に適用されない。
NOBOUND指令を指定した場合は、この一般規則は実行時に適用されない。
データ名には、指標名を3つまで指定できる。
![]() データ名には指標名を7つまで指定できる。
データ名には指標名を7つまで指定できる。
![]() データ名には指標名を16個まで指定できる。
データ名には指標名を16個まで指定できる。
指標付けの一般形式は、添字付け節に記した一般形式に含まれている。
![]()
関数一意名とは、関数を評価した結果として得られるデータ項目を一意に参照する名前である。この名前は、文字列と分離符を構文的に正しく組み合わせて付ける。
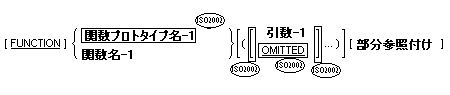
![]() ただし、以下の場合を除く。
ただし、以下の場合を除く。
![]() また、利用者定義関数に対する同規則は、手続き部の章のパラメータおよび返却する項目への準拠性で解説する。
また、利用者定義関数に対する同規則は、手続き部の章のパラメータおよび返却する項目への準拠性で解説する。
![]() 各国語の関数に対しても指定できる。
各国語の関数に対しても指定できる。
注:引数の有無にかかわらず、参照される関数(RANDOM関数など)については、正しく解釈されるよう、符号化に注意が必要である。以下に関数の例を示す。
FUNCTION MAX (FUNCTION RANDOM (A) B)
Aは、、RANDOM関数の引数と見なされる。このような関数で、AをMAX関数の2番めの引数とする場合は、以下のいずれかのように書かれなければならない。
FUNCTION MAX (FUNCTION RANDOM () A B) または
FUNCTION MAX ( (FUNCTION RANDOM) (A) B) または
FUNCTION MAX (FUNCTION RANDOM A B)
組み込み関数名-1が指定されている場合は、一時データ項目は、基本データ項目であり、その記述項と項類は組み込み関数の定義により指定される。この定義については、手続き部 - 組み込み関数の章の関数の定義で解説する。
![]() 関数プロトタイプ名-1が指定されている場合は、一時データ項目の記述、字類、および項類は、関数プロトタイプ名-1で指定された関数プロトタイプの手続き部見出しのRETURNING句で指定された項目の連絡節の記述により指定されたものである。
関数プロトタイプ名-1が指定されている場合は、一時データ項目の記述、字類、および項類は、関数プロトタイプ名-1で指定された関数プロトタイプの手続き部見出しのRETURNING句で指定された項目の連絡節の記述により指定されたものである。
![]() 利用者定義関数については、手続き部の章の手続き部見出しおよびパラメータおよび返却する項目の準拠性にある。
利用者定義関数については、手続き部の章の手続き部見出しおよびパラメータおよび返却する項目の準拠性にある。
![]() 整数の引数をとる関数では、浮動点引数が与えられた場合は、もっとも近い整数に値が丸められる。または、小数点以下は切り捨てられる。
整数の引数をとる関数では、浮動点引数が与えられた場合は、もっとも近い整数に値が丸められる。または、小数点以下は切り捨てられる。
![]() 関数プロトタイプ名-1が指定されている場合は、関数プロトタイプ名の適用規則で解説されている規則が指定される。その他に、環境部の章のリポジトリ段落節で解説する規則も指定される。
関数プロトタイプ名-1が指定されている場合は、関数プロトタイプ名の適用規則で解説されている規則が指定される。その他に、環境部の章のリポジトリ段落節で解説する規則も指定される。
![]() 関数プロトタイプ名-1が指定されており、起動される関数はCOBOL関数である場合は、手続き部の章の手続き部見出し節の解説に従って実行される。
関数プロトタイプ名-1が指定されており、起動される関数はCOBOL関数である場合は、手続き部の章の手続き部見出し節の解説に従って実行される。
組み込み関数名-1が指定されている場合は、手続き部 - 組み込み関数の章の解説に従って実行される。
![]() 関数プロトタイプ名-1が指定されており、起動される関数はCOBOL関数である場合は、使用しているCOBOLシステムのマニュアルのインターフェイスに関する記述における定義に従って実行される。
関数プロトタイプ名-1が指定されており、起動される関数はCOBOL関数である場合は、使用しているCOBOLシステムのマニュアルのインターフェイスに関する記述における定義に従って実行される。
部分参照(reference modification)とは、データ項目の一部を切り出してデータ項目を定義することである。切り出す範囲はデータ項目中の起点となる文字位置(切り出す文字の左端文字位置)と長さによって指定する。
一意名-1 ( 左端文字位置 : [長さ] )
![]() 外部浮動小数点数、
外部浮動小数点数、
数字編集、英字、英数字編集のどれかであるとき、部分参照の目的上、そのデータ項目は同じ大きさの英数字データ項目として再定義されたものとして操作される。
![]() 浮動小数点数形式の式では、結果は丸められる。固定小数点数形式の式では、結果は切捨てられる。
浮動小数点数形式の式では、結果は丸められる。固定小数点数形式の式では、結果は切捨てられる。
![]() 浮動小数点数形式の式では、結果は丸められる。固定小数点数形式の式では、結果は切捨てられる。
浮動小数点数形式の式では、結果は丸められる。固定小数点数形式の式では、結果は切捨てられる。
注: 左端文字位置と長さの評価により生成された値が正しいかどうかの確認は行われない。値が、この規則で述べられた制限に適合しない場合は、未定義の結果が生じ、他のデータ項目が破壊される可能性がある。
![]() 外部浮動小数点数
外部浮動小数点数
のものは、字類も項類も英数字とみなされる。
一意名(identifier)とは、データを一意に参照するために、文字列と分離符をいくつか 並べたものである。

プロパティ名-1 OF 一意名-1
行内呼出し-1
一意名-2 オブジェクトビュー-1

オブジェクト属性はオブジェクトからの情報の読出しおよびオブジェクトへの情報の書戻しを行うための特別な構文を形成する働きをする。オブジェクト属性にアクセスする仕組みとして、オブジェクト読出しメソッドとオブジェクト設定メソッドがある。オブジェクト読出しメソッドには、GET PROPERTY句を用いて明示的に定義したメソッドと、PROPERTY句を用いて記述されたデータ項目のために暗黙的に生成されるメソッドとがある。オブジェクト設定メソッドには、SET PROPERTY句を用いて明示的に定義したメソッドと、PROPERTY句を用いて記述されたデータ項目のために暗黙的に生成されるメソッドとがある。
![]()
行内呼出し-1は行内メソッド呼出し節で定義される。
![]()
オブジェクトビュー-1はオブジェクトビュー節で定義される。
![]()
番地指定子はデータ番地一意名節およびプログラム番地一意名節で定義される。
.各条件名は一意であるか、または修飾、指標付け、添字付けによって一意にしなければならない。条件名を一意にするために修飾する場合は、関連する条件変数を最初の修飾語として使用できる。修飾する場合、条件変数に関連する名前の階層系列または条件変数自体を使用して、条件名を一意にする。
条件変数を参照するのに指標付けまたは添字付けが必要な場合は、その条件名を参照するときにも、同じ組合わせの指標付けまたは添字付けを使用する。
条件名の修飾、指標付け、添字付けの組合わせの形式と制限は、一意名の場合のデータ名-1を条件名-1と置き換えたものと同じである。
一般形式において条件名というときは、必要に応じて修飾、指標付け、添字付けしたものを含む。
![]()
行内メソッド呼出しは、メソッドの呼出しにより返された一時データ項目を参照する。

行内メソッド呼出しは、適切な形式で実行されたINVOKE文により返された一時一意名と同じ字類、項類、および内容の一時データ項目を参照するものとする。INVOKE文の例を以下に示す。
INVOKE 一意名-1 定数-1 USING 引数 RETURNING 一時一意名ここで、
INVOKE 一意名-1 定数-1 RETURNING 一時一意名
INVOKE 字類名-1 定数-1 USING 引数 RETURNING 一時一意名
INVOKE 字類名-1 定数-1 RETURNING 一時一意名
![]()
オブジェクトビューにより、オブジェクト参照が指定された記述を持っているように取り扱われるようになる。実行時に、この記述が有効かどうか、オブジェクトが検査される。

![]()
データ番地一意名は、データ項目の番地を含む一意のデータ項目を参照する。
ADDRESS of 一意名-1

一意名-1または定数-1が指定される場合は、COBOL言語の概念の章のCOBOLの語節の解説に従って、この値を使用して参照先プログラムが識別される。
COBOLの原始要素には、下記の4種類の明示指定と暗黙指定がある。
COBOL原始要素プログラム中では、手続き部の文で、データ項目を明示的にも暗黙的にも参照できる。 明示参照(explicit reference)とは、手続き部の文に参照対象項目の名前を書いた場合、またはCOPY(複写)文、
![]() REPLACE文、
REPLACE文、
![]() INC文、または++INCLUDE文
INC文、または++INCLUDE文
を実行して参照対象項目の名前を手続き部に複写してきた場合の参照をいう。 暗黙参照(implicit reference)とは、手続き部の文に参照対象項目の名前を書かないでデータ項目を参照することをいう。
PERFORM(実行)文を実行する際にも、暗黙参照が発生する。これは、PERFORM文に関連する制御機構がVARYING句、AFTER句、UNTIL句に指定された指標名または一意名によって参照される、指標またはデータ項目を初期化したり変更したり評価したりした場合である。このような暗黙参照は、データ項目が命令の実行に係わるときだけ行われる。
制御の流れでは、書かれている順に文から文へと制御が移行する。ただし、この順序より優先される制御の明示移行が存在する場合、または制御を渡すことのできる次の実行可能な文が存在しない場合を除く。文から文への制御の移行は、手続き部文がとくに書かれていなくても行われる。したがって、制御の暗黙移行と呼ばれる。
COBOLには、暗黙的な制御移行の機構を明示的にも暗黙的にも変更する手段が備わっている。
制御の暗黙移行は、連続する完結文および連続する文の間で起こるほか、手続き分岐文を実行することなく通常の制御の流れを変えるときにも起こる。文から文への制御の流れを暗黙のうちに変更する方法には、以下のものがある。
注:その宣言部分の節に暗黙に制御が移る。この宣言部分の節が実行された後で、暗黙のうちに制御が戻る(上記1.を参照)。
USE AFTER ERROR PROCEDURE ON ファイル名.
IF 状態キー-1 >= 3
DISPLAY エラーメッセージ UPON CONSOLE
STOP RUN.
エラーメッセージの定義については、エラーメッセージを参照。
制御の明示移行とは、手続き分岐文または条件文を実行することによって、制御の暗黙移行の機構を変えることをいう。文の間の制御の明示移行は、手続き分岐文または条件文を実行することによってだけ引き起こされる。完結文の間の制御の明示移行は、IF(判断)文のNEXT SENTENCE(次の完結文)句またはSEARCH(表引き)文を実行することによってだけ引き起こされる。
手続き分岐文のALTER(変更)文を実行することは、直接的に制御の明示移行を引き起こす訳ではなく、関連するGO TO(飛び越し)文を実行するときの制御の明示移行に影響する。手続き分岐文のEXIT PROGRAM(プログラムの出口)文は、呼ばれたプログラムの中で実行されると、制御の明示移行を引き起こす。
「次の実行完結文」(next executable sentence)という用語は、上記の規則に従って制御が暗黙のうちに移されるか、またはNEXT SENTENCE句によって明示的に制御を移される、次のCOBOL完結文を指すために用いる。次の実行完結文は、現在の完結文を終了させる分離符の終止符の直後の完結文である。
「次の実行文」(next executable statement)という用語は、上記の規則および手続き部の各言語要素に関連する規則に従って制御が移される、次のCOBOL文を指すために用いる。
以下の場合には、次の実行文は存在しない。
![]() GOBACK(復帰)文、
GOBACK(復帰)文、
![]() EXIT
METHOD(メソッド出口)文、
EXIT
METHOD(メソッド出口)文、
![]() EXIT
FUNCTION(関数出口)文、
EXIT
FUNCTION(関数出口)文、
またはEXIT PROGRAM(プログラム出口)文。
属性は、暗黙的にも明示的にも指定できる。明示的に指定した属性を、明示属性(explicit attribute)という。属性を明示的に指定しないと、省略時の解釈が取られる。このような属性を、暗黙属性(implicit attribute)という。
たとえば、データ項目の用途(usage)は指定しなくてよい。指定のないデータ項目の用途はDISPLAY(表示用)と解釈される。
![]() PICTURE文字列が"G"または"N"を持たないを除く。この場合、データ項目の用途はDISPLAY-1である。
PICTURE文字列が"G"または"N"を持たないを除く。この場合、データ項目の用途はDISPLAY-1である。
![]()
範囲符は、手続き部のある種の文(範囲明示文)の範囲を区切る。これには、明示範囲符と暗黙範囲符の2種類がある。
有効な明示範囲符には以下のものがある。
END-ADD
END-PERFORM
![]() END-ACCEPT
END-ACCEPT
END-CALL
![]() END-CHAIN
END-CHAIN
END-COMPUTE
END-DELETE
![]() END-DISPLAY
END-DISPLAY
END-DIVIDE
END-EVALUATE
END-IF
END-MULTIPLY
END-READ
END-RETURN
END-REWRITE
END-SEARCH
END-START
END-STRING
END-SUBTRACT
END-UNSTRING
END-WRITE
注:COBOL言語の方言が異なると、範囲符と対になる範囲明示文が異なることがあるので注意。
暗黙範囲符は下記の場合に発生する。
Copyright © 2002 Micro Focus
International Limited. All rights reserved.
本書、ならびに使用されている固有の商標と商品名は国際法によって保護されています。
|
COBOL言語の概要 | 翻訳集団の概念 | |