【第2回】COBOL言語の方言

2025.04.23
既存 COBOL資産を、価格競争力のある新しい環境にモダナイゼーションする DX手法は多くの成功事例を生んでいますが、その要因の一つには COBOL言語が持つポータビリティ(移植性)の高さがあります。
はじめに
COBOLの言語仕様は ISO国際標準によって規格化されており、すべての COBOL言語処理系はこれに準拠していなければなりません。このため 50年前に書かれたプログラムが最新のコンピュータ上でもそのまま動作するという驚くべき特性があります。
方、長い歴史の中では多種多様なコンピュータ上で様々な COBOLコンパイラが提供され、各コンピュータ向けに COBOLプログラムが書かれ、利用されてきました。IBMメインフレームだけでも 60年の歴史の中で多くのバージョンの COBOLコンパイラ製品がありますし、富士通、日立、NECなどのメインフレームでそれぞれの COBOLコンパイラがバージョンを重ねて提供されてきています。 また、日本では「オフコン」と呼ばれる一連のミッドレンジコンピュータが各社から製品化されていた時代があり、そのそれぞれに多種多様な COBOLコンパイラがありました。Windows, Linux, UNIXと言ったオープン環境でも多くのバージョンの COBOLコンパイラが存在します。モダナイゼーションの対象となりうる既存 COBOL資産には、このような幅広いルーツがあるのですね。
これらの、様々な COBOLコンパイラは、すべて ISO国際標準に準拠しつつも、多くの場合、それぞれ独自の COBOL構文を追加でサポートしています。これを COBOL言語の「方言 (dialect)」と呼びます。方言は、主としてプラットフォームに特化したアプリケーション開発を簡易化し、生産性を向上させるために用意されています。その一方で、このような方言を使用して書かれたプログラムはポータビリティがなく、時としてモダナイゼーションの障壁となります。
本稿では、過去にどのような COBOL言語方言が、どのような背景で存在したのかを振り返り、それらが最新のプラットフォームでどのように活用し得るかについて考えてみます。
国際標準と方言
COBOLの言語仕様は ISO国際標準によって規格化されているわけですが、それではなぜこのような多様な方言が発生するのでしょうか。
この国際標準は、あるCOBOLコンパイラ・ランタイムがこの標準に準拠しているかどうかを判定するための規則を詳細に定めています。その条項の中に「拡張言語要素」というものがあり、標準で定められた言語機能ではないものを追加することを禁止してはい
ません。ここに様々な方言が発生する根拠があるのです。
ただし、同時にこの国際標準では以下のことも要請しています:
- このような「拡張言語要素」は言語のマニュアルの中で国際標準の範囲外であることを明記しなければならない
- プログラマーがそれをコンパイルする際に、国際標準の範囲外の言語要素を警告として通知される機能を持たなければならない
Visual COBOLの場合、この要請に応えるために COBOL言語リファレンスマニュアルの中で、Micro Focus*1拡張構文の個所には「MFマーク」を付与して明確化しています。また、コンパイラ指令の FLAG(ISO2002) を指定することによって、国際標準に規定されていないCOBOL構文の使用箇所を警告することができます。
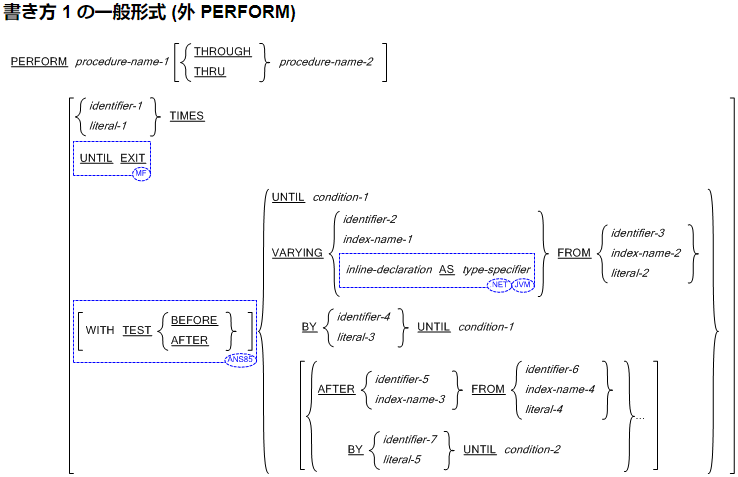
Visual COBOLのマニュアルより
方言部分がハイライトされています。
一方、COBOL言語以外の標準が COBOL言語への追加構文を規定することがあります。例えば、リレーショナルデータベースの照会言語である SQLも国際標準で言語仕様が規定されていますが、その中で既成のプログラミング言語内に SQLを埋め込む構文についても規定しています。これが、長年にわたって幅広く活用されている COBOL埋め込みSQL構文です。COBOLソースプログラム中に EXEC SQL … END-EXEC で囲まれる SQL文を埋め込むことで COBOLと SQLという二つの異なる言語を混在利用するもので、IBMメインフレーム上の Db2が提供する COBOLプリプロセッサや、Oracleが提供する Pro*COBOLなどの多くの実装があります。SQLの国際標準は、COBOLほどは厳密に定義されていないように見えますが、この埋め込みSQLにも多くの方言が存在している現状があります。
方言の目的と種類
本稿ではこの後で様々方言について見ていきますが、その前にそれらの方言がどんな背景で登場したのかをざっと見ておきましょう。COBOL言語の方言は、主に以下のような背景で生まれてきています。
- 本来標準化されるべきだったが、標準が追い付かずに勝手に製品化されてしまったもの
COBOL言語の国際標準は過去に何度かの改訂がなされており、その都度、時代の要請する新たな言語機能を標準化してきています。ところが、その多くは標準化される前に各社の COBOLコンパイラによって先んじて実装されてしまっており、それらに微妙な差異が発生していました。標準化された後はそれらが方言として残される結果となりました。
この後の章で述べる、日本語対応や画面処理、オブジェクト指向などがこのタイプに属します。 - データベースやトランザクションモニターなどのミドルウェアが、COBOL言語APIを提供する目的で実装したもの
埋め込み SQLについてはすでに述べましたが、その他にも COBOL言語の外部から APIを提供する目的で提供された COBOL埋め込み構文が存在します。この後の章でこれらについても述べます。 - 単に便利だから勝手に追加したもの
COBOLを最初に学ぶときに “IDENTIFICATION DIVISION” という長ったらしい記述に驚く、というお約束がありますが、IBMメインフレームの COBOLはこれを “ID DIVISION” と省略することを許しています。納得のゆく便利さですね。でもこれも方言です。 - プラットフォーム固有の資源にアクセスするために必要となって追加したもの
もともとメインフレームのアーキテクチャで実行されることを想定していた COBOLですが、UNIX上で使用されるようになるとそこでのシステム記述言語である C言語とのインタフェースが必須となり、ポインタ操作などが方言として追加されました。同じ理由で、現在では Java VM上や .NET Framework上で使用される場合に必要となる方言も追加されています。
IBMメインフレームの方言
IBMは最も早く COBOLコンパイラを実装したメーカーであり、現存するCOBOLプログラムのうちおそらくもっとも多くの部分が IBMメインフレーム上で稼働していると思われます。その IBMが最初にCOBOLを実装したときから既に方言はありました。 “ID DIVISION” については上で述べましたが、他によく知られているものに GOBACK文があります。この文は国際標準では規定されていません。GOBACK文と STOP RUN文の意味は若干異なるのですが、STOP RUN文の代わりに幅広く利用されている方言です。 この他に IBMメインフレームの COBOLに古くからある方言としては、EXAMINE文、ON文などがありますが、これらは IBM自身が後続の COBOLコンパイラでは廃止にしています。
一方、現在最新の IBM Enterprise COBOLは、バージョンを重ねるごとに新しい言語機能を積極的に追加しており、進化を続けています。これによって COBOL方言は更に増えてゆく結果となっています。
このような IBMメインフレームのCOBOL方言は、Visual COBOLを含む多くの COBOLコンパイラによって互換性サポートされています。特に、コンパイラの IBMメインフレーム互換モードをサポートしており、COBOL方言に関しては、ほぼすべてそのまま再コンパイルして利用することができます。
USAGE句の拡張
COBOLの数字データ項目についてその内部格納形式の詳細を定めるために USAGE句があります。プラットフォームによって算術演算の処理効率の高い内部形式は異なるため、COBOLコンパイラによって USAGE句の記述には相違が発生します。

USAGE句による数字内部表現形式の指定
国際標準では USAGE COMP と書かれた項目の内部表現の詳細は規定されておらず、各 COBOLコンパイラが独自に定めてよいものとなっています。USAGE COMPは計算用の項目という意味ですから、そのプラットフォームで最も高速に計算できる形式にする習いとなっており、現在ほとんどのコンパイラではこれを 2進表現と解釈しています。しかし、コンパイラによってはこれをパック十進形式と解釈するものもありました。
さらに、各コンパイラは国際標準に規定されていない表現形式に対応するために USAGE句の追加を行っています。代表的なものが COMP-1, COMP-2, COMP-3, COMP-4, COMP-5 です。IBMメインフレームでは COMP-1 と COMP-2 はそれぞれ単精度・倍制度浮動小数点形式を表しており、Visual COBOLもこれに従っています。しかし、そうではない解釈をするコンパイラも存在します。
日本語拡張
Unicode登場以前には、漢字や全角カタカナを2バイトのコードで表現する方式が主流であり、そのコード化は JISなどで標準化されているほか、IBM、富士通、日立、NECなど各社が拡張漢字仕様を定めていました。COBOLでもこれらの2バイト文字を活用できるための機能が必要でしたが、そのための国際標準の制定は ISO2002標準まで待たなければなりませんでした。
このため、各社の COBOLコンパイラはそれぞれの仕様で、2バイト文字型の PICTURE文字列や、2バイト文字定数の書き方を実装してしまったのです。このため、2バイト文字型の文字定数を書く方法として、N’漢字’、G’漢字’、NC’漢字’ などの様々な方法が方言として存在しています。遅れて制定された国際標準では N’漢字’ が採択されており、それ以外は方言として残っています。
これらの日本語処理に関する方言は、モダナイゼーションの障壁になることはほとんどありません。簡単な自動変換によって標準的な文法に書き換えることができるからです。
2バイト文字によるコード化は、画面や帳票上に印字される文字幅がデータのバイト長と一致するという利点がありました。COBOL言語の REPORT SECTIONを使用した帳票機能などは、これが成立しなければ正しいカラム位置へ印字しません。シフトJISも同じくこの利点があります。一方、Unicodeはそうではありません。UTF-16は、全角文字も半角文字も等しく一文字2バイトで表現しますし、一般的な UTF-8 は半角カタカナを3バイトで表現するなどのずれがあります。
COBOLのREPORT SECTION構文で生成される帳票のイメージ
このため COBOLにおける Unicodeは、他の言語と比べて普及速度がゆっくり目なようで、国際標準化が間に合った感があります。これについては、各社がほぼ標準に準拠した同じ実装を行っており、方言はあまり発生していません。
データベース拡張
COBOLにはレコード単位ファイル入出力が言語仕様として装備されており、READ文、WRITE文などによって高度な処理を簡潔に書くことができます。特にレコードへのランダムアクセスを可能とする索引編成ファイルは、IBMメインフレームで実装された VSAMをはじめとして多くの実装があります。これらは、若干の方言はあるもののほぼ国際標準に準拠しているため、既存のCOBOLプログラムを活用したモダナイゼーションは難しくありません。
一方、索引編成のようないわゆる「フラットファイル」によるプログラミングの煩雑さや、データの一貫性・完全性問題を解決することを目的として、1960年代から様々なデータベース管理システム (DBMS) が各社によって開発され始めました。IBMは、アポロ計画に必要な膨大な部品管理をターゲットとして、階層型DBMSであるIMSの初版を 1968年にリリースしています。同じころ、COBOL言語の標準化作業を担当した委員会であるCODASYLも DBMSの標準化を推進し、ネットワーク型DBMSの仕様策定を行いました。この CODASYL仕様は幅広く普及はしませんでしたが、これに影響された多くの実装が日本国内のコンピュータベンダーを含めてなされました。
これらの、リレーショナルDBMS以前のデータベースに COBOLからアクセスする方法はそれぞれ異なっており、以下のようなパターンに分類されます。
- 関数呼び出し型
COBOLの CALL文で API関数を呼び出す方法です。IMSの場合、一連の CALL ‘CBL2DLI’ USING … という APIが用意されています。 - 独自構文型
索引編成ファイルに対する READ/WRITEと同様に、追加されたCOBOLの文を使用する方法です。CODASYL仕様にのっとった OBTAIN/MODIFY/ERASE文などが使用されます。 - COBOL埋め込み型
リレーショナルDBMSに対する EXEC SQL文と同様にクエリーを EXEC文によってCOBOLに埋め込む方法です。IMSの EXEC DLI文や、ADABASの EXEC ADABAS文などが普及しています。
このようなアプリケーションのモダナイゼーションは一般には簡単ではありません。リレーショナルDBMSとはモデルが異なりますので機械的な変換が難しいのです。唯一IMSに関しては、Enterprise Developerの提供する IMS互換機能を使用すれば COBOLの書き換えを必要とせずに Windows、Linux上で稼働させることができ、プラットフォームのモダナイゼーションは容易です。
IMS以外のレガシーDBMSについては、マイグレーションパートナー様に、このようなモダナイゼーションについての知見が蓄積されており、高い精度での自動変換を実現されています。
画面処理拡張
COBOLが最初に登場した頃、COBOLで書かれるプログラムはバッチ処理が主流でした。しかし、ほどなくしてリアルタイム処理への要求が発生し、オンライントランザクションの概念が登場しました。IMSは、階層型DBの他にメッセージキューベースのトランザクションモニターを装備していましたが、この中に利用者端末を使用したパネル入出力が実装されました。IBMはその後トランザクションモニター CICSをリリースしますが、そこにも BMSという端末パネル入出力機能が提供されました。
これらはメインフレームのトランザクション処理として提供されたものですが、日本国内各社のオフコンや、各種ミッドレンジコンピュータでは、より簡易なヒューマンインターフェイスを持つ対話型のアプリケーションが COBOLで書かれるようになりました。当時は Windowsのような GUIが登場する以前のことですので、”グリーンスクリーン” と言われる縦25行、横80桁のキャラクタ画面での操作がほとんどでした。
「グリーンスクリーン」
SCREEN SECTIONはこのような画面操作をCOBOLで行う方法の代表的な構文です。データ部に新設された SCREEN SECTIONで定義された画面レイアウトを ACCEPT/DISPLAY文で入出力するものです。画面パネルの中の固定テキストや入出力フィールドに対して、行・桁位置と色・罫線のような属性を固有な構文で記述します。この方法も古くから多くのCOBOLコンパイラによってサポートされていましたが、国際標準で規定されたのは21世紀になってからでした。このため、COBOLコンパイラによってフィールド属性の記述や手続き部の記述方法などに相違が発生しており、方言となっています。
このようなタイプのアプリケーションのモダナイゼーションに当たっては、旧弊なパネル入出力は廃止し、モバイル端末などからも利用可能なヒューマンインターフェイスに作り変えてしまうのが普通です。このほかに、書き換えコストを削減するために機械的な自動変換によって Visual COBOLのサポートする SCREEN SECTION構文に適合させてプラットフォームモダナイゼーションを行う方法も一般的です。
オブジェクト指向COBOLとMicro Focus拡張
COBOL言語にオブジェクト指向の概念を追加する取り組みは 1990年代にはじまりました。国際標準化の委員会の場で活発に議論が重ねられ、ISO2002 COBOLにて仕様が標準化しました。この仕様は、COBOLにオブジェクト指向言語の持つ一般的な概念を追加したもので、純粋な言語仕様でした。この点で Javaが Java VMというオブジェクト指向ランタイムシステムとペアで登場したのとは異なっていました。
Micro Focus*1は、この標準化活動に積極的に貢献すると同時に、先行する実装を活発に行いました。1993年には世界で初となるオブジェクト指向 COBOLを製品に追加してリリースしました。Micro Focus*1 Object COBOLは、ISO標準と同様に純粋に言語としてのオブジェクト指向をサポートしており、このために独自のオブジェクト指向ランタイムシステムを装備していました。しかし、それと同時にその当時普及していたオブジェクトモデルである Windowsの COM (当時は OLEと呼ばれていました) や、Java VMへのアダプタを装備し、COBOL言語からそれらのクラス・メソッドにアクセスできる機能を装備したため、こちらが COBOLプログラムのモダナイゼーションを可能にするものとして利用が広まってゆきました。この取り組みは、その後 .NET COBOLや JVM COBOLへと進化してゆきます。

Micro Focus*1 Visual Object COBOL (1996)
Micro Focus*1のオブジェクト指向拡張は、標準化に先んじて実装された上に、言語としてのオブジェクト指向より Javaや .NETとの連携を意識したために、ISO2002で標準化された文法とは差異があり、方言となりました。しかし、現実的には純粋なオブジェクト指向言語としての COBOLは普及してはおらず、既存の非オブジェクト指向のCOBOLロジックを Javaや .NETの世界で再利用するラッピング機能としての利用が広まっているため、この方言がモダナイゼーション障壁になることはありません。
構造化プログラミング方言
「構造化プログラミング」という言葉があります。これは、プログラムのロジック分岐を以下の3種類で統一的に記述し、GO TO分岐を使用しないというものです:
- IF … THEN … ELSE … END-IF
- PERFORM UNTIL … END-PERFORM
- EVALUATE … WHEN … … … END-EVALUATE
この規則に従って書かれたプログラムは可読性が高く、品質が確保されると言われています。しかし、COBOLが最初に登場した時代にはこの手法はまだ提唱されておらず、最初の COBOL標準では GO TO文を使用するしかありませんでした。
1985年に制定されたいわゆる COBOL 85標準で構造化プログラミング機能が制定されましたが、これがやや遅きに失しました。標準化に先立って、構造化プログラミングで書かれた COBOLソースファイルを、GO TO文を使用した旧標準の範囲内でのプログラミングに自動変換するプリプロセッサが各社によって開発されたのです。
NECの COBOL/S はその代表的なものです。

COBOL/S の構造化文
言語の機能としては COBOL 85 標準とほぼ同等のものを提供していますが、その記法は独自なものであり、方言として残ってしまいました。このようなプリプロセッサ型の拡張COBOLは、ベンダー提供のものだけではなく、大規模ユーザでは自社での独自の開発標準を定め、その一環としてこのような独自プリプロセッサを標準使用するという実践もなされました。
このような構造化拡張構文は、いずれも比較的簡単に COBOL 85 標準の構文に自動変換することができ、変換後のソースプログラムは Visual COBOLでコンパイルして再利用できます。
おわりに
本稿では様々な COBOLの方言を見てきました。このような方言で書かれた COBOLプログラムの中にも、いまだにビジネス価値を生み出し続けているものがたくさんあり、これを活用してモダナイゼーションすることで、低コスト低リスクの DXを実現することができます。
具体的な方法はケースバイケースとなりますが、方法はあるとお考え下さい。
*1「Micro Focus」はOpenTextの登録商標です。本記事における「Micro Focus」の使用は、過去の製品名や企業名の参照を目的としたものであり、Rocket SoftwareはOpenTextとは提携していません。現在、これらの製品(Visual COBOL、Enterprise Developerなど)はRocket Softwareが提供・サポートしています。
関連情報
オンライントレーニング:Learn COBOL in 1Day
COBOLの基礎を短時間で習得できるオンライントレーニングプログラムです。シミュレーションやクイズを通じて、COBOLに関する強固な基礎知識を身につけることができます。
セミナー:COBOL言語超入門セミナー
これからCOBOL言語を知ろうとするエンジニア向けの入門セミナーです。プロジェクト管理者、システム管理者、マイグレーションエンジニア等の方々を対象に、COBOL言語を使用するシステム開発のための基礎知識を提供します。
Enterprise Developer
Enterprise Developer は、IBMメインフレームで稼働しているバッチ / オンラインアプリケーションをオープン環境で有効に活用できる製品です。
Visual COBOL
Visual COBOLは、最新版のCOBOL統合開発環境製品です。価値ある既存COBOL資産の最新テクノロジー環境での活用を可能にします。単一のCOBOLソースを多数のプラットフォームに展開することができるため、開発期間の短縮やコスト削減にも貢献します。


